Отговорът на този въпрос може да бъде получен с генериране на асоциативни правила. Това е често срещана задача в сферата на машинното обучение. При нея се търсят зависимости между множества от елементи (обекти или събития), които след това се
представят под формата на правила и се използват за различни цели като например при изследване на потребителско поведение. Алгоритми за решаване на подобни задачи са например Apriori, FP-Growth и др.
Асоциативните правила са във вид:
ако {списък_от_елементи} => {следствие}
Списъкът от елементи още се нарича antecedent, а следствието – consequent.
Как работи алгоритъмът Apriori?
Apriori е алгоритъм, позволяващ откриване на обекти, които често се срещат заедно. Това става на базата на предварително зададен праг (threshold) за честота на срещане. Apriori генерира подмножества, които могат да бъдат огромен брой дори ако продуктите в извадката са малко. Първо алгоритъмът изчислява честотата на срещане на индивидуалните продукти и премахва тези, при които тя е под зададения праг, след това продължава с комбинации от 2 продукта, после с 3 и т.н. докато не се отсеят всички излишни подмножества.
Например в следната таблица можете да видите 5 транзакции, в които участват определени хранителни продукти.
| TP | хляб (Х) | месо (М) | бира (Б) | вода (В) | яйца (Я) |
|---|---|---|---|---|---|
| TP1 | 1 | 1 | 1 | 0 | 0 |
| TP2 | 1 | 0 | 1 | 0 | 1 |
| TP3 | 0 | 1 | 1 | 1 | 0 |
| TP4 | 1 | 1 | 1 | 0 | 0 |
| TP5 | 1 | 1 | 0 | 1 | 0 |
Ако приемем, че сме задали като минимален праг 0.3, алгоритъмът ще премахне тези продукти, които се срещат в по-малко от 30% от всички транзакции.
Стъпка 1 – преглед на честотата на срещане на индивидуалните продукти.
| Х | М | Б | В | *Я* |
|---|---|---|---|---|
| 0.8 | 0.8 | 0.8 | 0.4 | 0.2 |
В нашия случай яйцата попадат под праговата стойност и съответно се премахват от по-нататъшните разглеждания. Apriori работи на принципа, че ако един продукт е рядко срещан, то комбинациите с него също са.
Стъпка 2 – преглед на комбинациите от 2 продукта
| Х-М | Х-Б | *Х–В* | М–Б | М–В | *Б–В* |
|---|---|---|---|---|---|
| 0.6 | 0.6 | 0.2 | 0.6 | 0.4 | 0.2 |
Две от комбинациите (хляб-вода и бира-вода) са под зададения праг и се премахват.
Стъпка 3 – преглед на комбинации от 3 продукта
| Х-М-Б |
|---|
| 0.4 |
Остава само една възможна комбинация, която е над зададения праг, след което алгоритъмът приключва работа.
Критерии за оценка
До колко добре са асоциациите можем да определим чрез различни метрики за оценка.
- Поддръжка (support, coverage) – какъв процент от анализираните случаи съдържат определено множество от елементи
supp(A\rightarrow T) = P(A\cup T)- Достоверност (confidence, accuracy) – вероятността от частта списък от елементи да следва частта следствие.
confidence(A\rightarrow T) = \frac{P(A\cup T)}{P(A)} = \frac{supp(A\rightarrow T)}{supp(A)}- Подемна сила (lift) – показва дали има зависимост между определени обекти или те присъстват заедно по случайност
lift(A\rightarrow T) = \frac{conf(A \rightarrow T)}{supp(T)}=\frac{supp(A \rightarrow T)}{supp(A)\times supp(T)}-
lift > 1 има положителна зависимост и шанса обектите да се срещнат заедно е по-висок.
-
lift < 1 има отрицателна зависимост и шанса обектите да се срещнат отделно е по-висок
-
lift = 1 наличието на списъка от елементи няма влияние върху следствието
-
Влияние, натиск (leverage) – колко по-вероятно е определени обекти да се срещат заедно отколкото поотделно
leverage(A\rightarrow C) = P(X \cap Y) - P(X) \times P(Y) = {support}(A\rightarrow C) - {support}(A) \times{support}(C) Например, ако имаме продажби на хранителни стоки, целта е да разберем с колко повече конкретни продукти се закупуват заедно отколкото индивидуално.
- Убеденост (conviction) – до каква степен асоциацията между списъка от елементи и следствието е неправилна
conviction(A\rightarrow C) = \frac{1 - {support}(C)}{1 - {confidence}(A\rightarrow C)} = \frac{P(X) \times P(\overline Y )}{P(X \cap \overline Y)}Изчислява се съотношението между пропорцията от транзакции, в които не присъства следствието и вероятността асоциацията да е неправилна.
Например ако получим като стойност за тази метрика 1.4, тогава асоциацията ще е неправилна 40% по-често отколкото ако тя се дължи на случайност (когато е метриката е равна на 1).
Практическа задача
Извадката, която ще използваме, съдържа данни за продажби на хранителни стоки (9835 транзакции за 30 дневен период). Задачата ни е да намерим кои продукти с кои други най-често се закупуват. За решението ѝ ще използваме библиотеката Mlxtend на Python. Тя съдържа функция apriori(), с която ще генерираме често срещани подмножества от елементи и функция association_rules(), която използва получените данни и генерира асоциативни правила.
Пет случайни реда от извадката изглеждат по следния начин:
| Items | |
|---|---|
| 3859 | pip fruit,canned beer |
| 9774 | white bread |
| 3725 | chicken,beef,yogurt,rolls/buns,newspapers |
| 9747 | rolls/buns,pastry,soda |
| 2191 | chicken,hamburger meat,other vegetables |
- Откриване на броя и честотата на закупуване на всеки продукт
# Разделяне на продуктите поотделно
items = df['Items'].str.findall('[^,]+').sum()
# Запазване на продуктите в нов DataFrame
df_items = pd.DataFrame(items, columns=['Items'])
# Откриване на броя закупени продукти
df_items = df_items.value_counts().to_frame('Count')
# Нулиране на индекса
df_items.reset_index(inplace=True)
# Откриване на честотата на закупуване на продуктите
df_items['Freq'] = df_items['Count']/df.shape[0]| Items | Count | Freq | |
|---|---|---|---|
| 0 | whole milk | 2513 | 0.255516 |
| 1 | other vegetables | 1903 | 0.193493 |
| 2 | rolls/buns | 1809 | 0.183935 |
| 3 | soda | 1715 | 0.174377 |
| 4 | yogurt | 1372 | 0.139502 |
В таблицата можете да видите 5-те продукта, които са закупени най-често.
# Намиране на топ 10 продукти според честотата
df_items_top = df_items.nlargest(10, 'Freq')
# Изграждане на стълбовидна диаграма
ax = sns.barplot(data=df_items_top, x='Items', y='Freq')
ax.set_xticklabels(ax.get_xticklabels(), rotation=40, ha=right)
plt.tight_layout()
plt.show()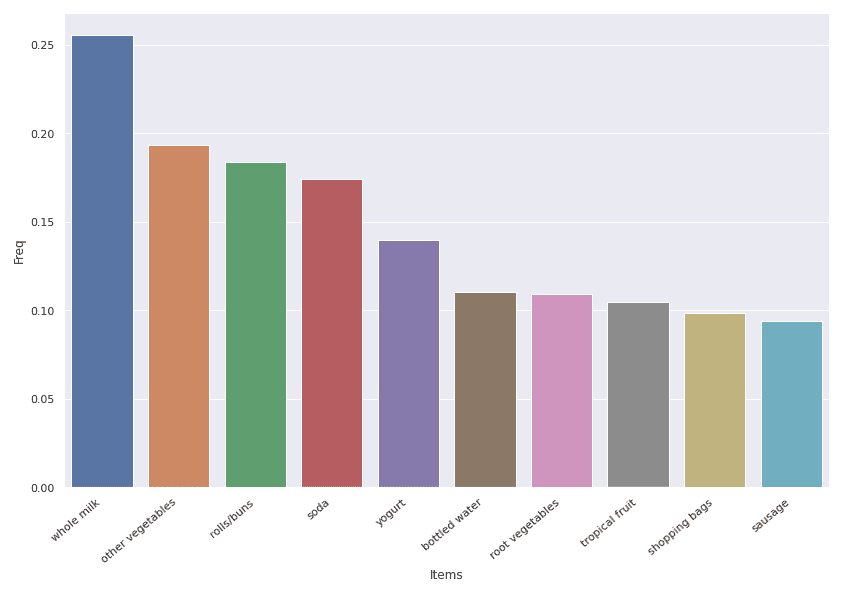
На сълбовидната диаграма са представени 10-те най-често купувани продукти, като те са подредени в низходящ ред според честотата на закупуването им. На първо място е пълномасленото мляко, което присъства в 26% от всички транзакции, а на десето е наденицата, закупувана в 9% от всички случаи.
- Използване на алгоритъма Apriori и генериране на асоциативни правила
Необходимо е първо да обработим данните, за да можем след това да ги подадем като параметър на функцията apriori().
# Разделяне на продуктите в отделни колони
splitted = df['Items'].str.split(',', expand=True)
# Създаване на списък с транзакциите
records = []
for i in range(splitted.shape[0]):
records.append([str(splitted.values[i,j]) for j in range(splitted.shape[1])])
# Използване на TransactionEncoder() и създаване на подходящият DataFrame за функцията
te = TransactionEncoder()
te_ary = te.fit(records).transform(records)
sparse_df = pd.DataFrame(te_ary, columns=te.columns_)
sparse_df.drop('None', axis=1, inplace=True)Нужно е да създадем отделна колона за всеки продукт. В редовете, където присъства той, се поставя стойност 1, а там където не присъства – 0.
В следната таблица може да видите как изглеждат 5 случайни реда за двата най-продавани продукта – пълномаслено мляко и други зеленчуци.
| whole milk | other vegetables | |
|---|---|---|
| 6704 | 1 | 0 |
| 3042 | 0 | 0 |
| 8862 | 1 | 1 |
| 902 | 1 | 0 |
| 6773 | 0 | 1 |
Цялата таблица след обработката е с 9835 реда и 169 колони. Преди да я подадем на apriori(), трябва да изчислим минимален праг.
Нека да приемем, че ни интересуват само онези продукти, които се продават по 5 пъти на ден и тъй като данните ни са за 30 дни, от тук можем да изчислим като праг 5 * 30 / 9835 = 0.015.
# Прилагане на алгоритъма Apriori
df_apriori = apriori(sparse_df, min_support=0.015, use_colnames=True, verbose=1)
# Откриване на асоциативни правила чрез функцията association_rules()
rules = association_rules(df_apriori, metric=support, min_threshold=0.015)Алгоритъмът е генерирал 238 на брой правила.
| antecedents | consequents | antecedent support | consequent support | support | confidence | lift | leverage | conviction | antecedent_len | |
|---|---|---|---|---|---|---|---|---|---|---|
| 180 | yogurt | shopping bags | 0.139502 | 0.0985257 | 0.0152517 | 0.109329 | 1.10965 | 0.00150715 | 1.01213 | 1 |
| 27 | yogurt | bottled water | 0.139502 | 0.110524 | 0.0229792 | 0.164723 | 1.49039 | 0.00756091 | 1.06489 | 1 |
| 107 | pork | other vegetables | 0.0576512 | 0.193493 | 0.0216573 | 0.375661 | 1.94148 | 0.0105023 | 1.29178 | 1 |
| 203 | whole milk, rolls/buns | other vegetables | 0.0566345 | 0.193493 | 0.0178953 | 0.315978 | 1.63303 | 0.00693692 | 1.17907 | 2 |
| 127 | pastry | rolls/buns | 0.088968 | 0.183935 | 0.0209456 | 0.235429 | 1.27996 | 0.00458129 | 1.06735 | 1 |
Таблицата представя 5 случайно избрани правила, както и различните метрики за оценка. Например на ред 203 в 18% от случаите пълномаслено мляко и хлебчета са закупувани заедно, а в 32% от всички транзакции това е довело до закупуване на други зеленчуци. Стойността на подемната сила е 1.63, т.е. има положителна зависимост между продуктите за това правило и шанса те да се срещат заедно е по-висок.
- Анализ на получените резултати
След като имаме генерирани асоциативни правила и стойности за отделните метрики за оценка, можем с помощта на различни визуализации да представим нагледно тези, които са по-важни.
# Филтриране на резултатите за правила с confidence >= 0.25
rules_filtered = rules[(rules['confidence'] >= 0.25)]
# Създаване на интерактивна диаграма на разсейването
fig = px.scatter(rules_filtered, x='support', y='lift', color='confidence', color_continuous_scale='reds')
fig.show()На визуализацията можете да видите връзката между метриките поддръжка и подемна сила за данни, при които достоверността >= 0.25, като цветовете на точките се определят в зависимост от стойността на достоверността. Колкото по-висока е тя, толкова по-червен е цветът.
На следващата графика, ще видим връзката между продуктите в колоната със списъка от елементи и тази със следствията за филтрираните данни. Силата на връзката ще се определя от метриката подемна сила.
# Настройки на осите x и y
axis_template_x = dict(title='LHS', showticklabels=False, ticks='' )
axis_template_y = dict(title='RHS', showticklabels=False, ticks='' )
# Изграждане на визуализацията
fig = go.Figure(data = go.Heatmap(x=rules_filtered['antecedents'],
y=rules_filtered['consequents'],
z=rules_filtered['lift'],
colorscale='Reds',
hovertemplate=
'<br>%{x} -> '+
'<b>%{y}</b>' +
'<br><i>Lift</i>: %{z:.2f}'))
fig.update_layout(xaxis=axis_template_x,
yaxis=axis_template_y,
showlegend=False,
width=700,
height=700,
autosize=False)
fig.show()На визуализацията се вижда, че някои от правилата имат подемна сила със стойности над 2.5. Такива са например {whole milk, other vegetables} -> {root vegetables} и {beef} -> {root vegetables}, което означава, че тези продукти много често се закупуват заедно.
Можем да видим разликите в стойностите за отделните характеристики със следващата визуализация – паралелна диаграма.
# Изграждане на паралелна диаграма
fig = px.parallel_coordinates(rules_filtered, color='lift',
dimensions=['confidence', 'antecedent_len', 'leverage', 'conviction', 'support'],
color_continuous_scale=px.colors.diverging.Tealrose,
color_continuous_midpoint=2)
fig.show()При паралелната диаграма виждаме за всеки един ред какви са стойностите на конкретни характеристики. Можем да проследим как се изменят те и да правим сравнения между тях. В нашия пример отново използваме данните с достоверност >=
0.25, като прави впечатление това, че правилата, които имат висока подемна сила, предимно съдържат 2 продукта в колоната със списъка от продукти.
За следващата визуализация ще използваме само данни, където стойностите в колоната подемна сила са >= 1.8.
На графиката можете да видите различните продукти и броят връзки между тях. С най-голям брой връзки са други зеленчуци – 12. Също с голям брой връзки са пълномасленото мляко и йогуртът – 7 и 8.
Кода за тази графика можете да намерите в цялостното решение на задачата.
Извод
Можем да кажем, че най-често след като се закупува пълномаслено мляко и кореноплодни зеленчуци, се купуват и други зеленчуци. Също покупките на йогурт, масло или извара най-често ще доведе до покупка на пълномаслено мляко.
На базата на получените резултати можем да определим кои продукти да сложим близо едни до други или ако имаме система за препоръки, да се правят предложения за продукти, които клиентите биха харесали.
Искате да научите повече за Python?
Включете се в курса по програмиране с Python.
Автор: Десислава Христова