Кога имаме небалансирана извадка?
В много от случаите при решаване на задачи за класификация с методите на машинното обучение попадаме на извадка, при която представителите на класовете в целевата променлива не са равномерно разпределени, т.е. броят на обектите, принадлежащи към един клас, е значително по-различен от на този на другите класове. Тогава казваме, че тя не е балансирана.
Защо е необходимо да работим с балансирана извадка?
Представете си, че имаме извадка с данни за студенти. Тя включва следните характеристики: брой отсъствия, изпратени домашни, оценки и целева променлива, съдържаща 2 класа - преминали в следващ курс и непреминали. На базата на тези данни трябва да се построи класификатор, който да определя дали преминава или не студентът в следващ курс.
- Общо студенти: 130
- Брой преминали студенти: 120
- Брой непреминалите студенти: 10
В този случаи имаме много силно небалансирана извадка, защото студентите, които са преминали курса, представляват 92% от данните. Това означава, че без да се използват методи за машинно обучение, ако се опитаме сами да отгатнем на случаен принцип и кажем, че студентът преминава курса, в 92% от случаите ще бъдем прави. Това би обезсмислило използването на методи за машинно обучение.
В тази статия ще ви запозная с различните методи за балансиране на извадка, които предоставя библиотеката imblearn на Python.
За примерите, които ще видите по-надолу, ще използваме данни, които са синтетични. Те съдържат характеристики за възрастта и заплатата на служители, а целевата променлива се състои от 2 класа - дали са получили или не повишение, т.е. имаме случай на бинарна класификация.
df = pd.DataFrame({'Age': [28, 41, 60, 44, 24, 55, 50, 60, 70, 25, 52, 48, 58, 68, 36, 26, 39],
'Salary': [1600, 2550, 850, 1780, 1250, 1000, 2000, 1583, 580, 1488, 1055, 2450, 3560, 1700, 2425, 1450, 2230],
'Promotion': ['No','No','No','No','No','Yes','Yes','No','No','No','Yes', 'No', 'Yes', 'No', 'Yes','No','Yes']})Резултат:
| Age | Salary | Promotion | |
|---|---|---|---|
| 0 | 28 | 1600 | No |
| 1 | 41 | 2550 | No |
| 2 | 60 | 850 | No |
| 3 | 44 | 1780 | No |
| 4 | 24 | 1250 | No |
| 5 | 55 | 1000 | Yes |
| 6 | 50 | 2000 | Yes |
| 7 | 60 | 1583 | No |
| 8 | 70 | 580 | No |
| 9 | 25 | 1488 | No |
| 10 | 52 | 1055 | Yes |
| 11 | 48 | 2450 | No |
| 12 | 58 | 3560 | Yes |
| 13 | 68 | 1700 | No |
| 14 | 36 | 2425 | Yes |
| 15 | 26 | 1450 | No |
| 16 | 39 | 2230 | Yes |
- Общо служители: 17
- Брой получили повишение (клас Yes): 6
- Брой неполучили повишение (клас No): 11
X=df.drop(['Promotion'], axis=1)
y=df['Promotion']Разделяме данните в променливите X и y. В първата са отделните характеристики за всеки служител, а във втората е целевата променлива.
Библиотеката imblearn
Oversampling
Oversampling е техника за балансиране на извадка, при която се увеличава броят на обектите в по-малкото множество (minority), така че да се изравни с броя в по-голямото (majority).
- SMOTE
SMOTE (Synthetic Minority Oversampling Technique) е често използван метод за балансиране на извадки. Той генерира синтетично нови обекти, като използва алгоритъма k най-близки съседи (kNN). Броят съседи предимно е 5 и методът работи, като произволно избира един от тях, след което се създава нов сходен запис за класа с по-малко представители.
sm = SMOTE(random_state=2)
X_res_smote, y_res_smote = sm.fit_sample(X, y.ravel())Новите записи:
| Age | Salary | Promotion | |
|---|---|---|---|
| 18 | 47 | 3009 | Yes |
| 19 | 46 | 1494 | Yes |
| 20 | 50 | 1845 | Yes |
| 21 | 51 | 3218 | Yes |
- RandomOverSampler
Методът RandomOverSampler работи, като произволно дублира редове от по-малкото множество докато броя на представителите в класовете не се изравни. Прилагането на този метод би могло да доведе до преобучение (overfitting), тъй като моделът вижда повтарящи се записи, особено и ако те са много на брой.
ros = RandomOverSampler(random_state=2)
X_res_ros, y_res_ros = ros.fit_sample(X, y.ravel())Новите записи:
| Age | Salary | Promotion | |
|---|---|---|---|
| 18 | 39 | 2230 | Yes |
| 19 | 55 | 1000 | Yes |
| 20 | 58 | 3560 | Yes |
| 21 | 52 | 1055 | Yes |
- ADASYN (Adaptive Synthetic)
Това е метод, който адаптивно генерира синтетични данни за класът с по-малко представители, използвайки алгоритъма k най-близки съседи. Разликата между този метод и SMOTE е фактът, че ADASYN взима плътността на разпределението на данните като критерий, за да прецени колко нови обекта да генерира.
ada = ADASYN(random_state=2)
X_res_ada, y_res_ada = ada.fit_sample(X, y.ravel())Новите записи:
| Age | Salary | Promotion | |
|---|---|---|---|
| 18 | 46 | 2075 | Yes |
| 19 | 48 | 1335 | Yes |
| 20 | 49 | 3127 | Yes |
| 21 | 43 | 1861 | Yes |
Обобщаваща визуализация:
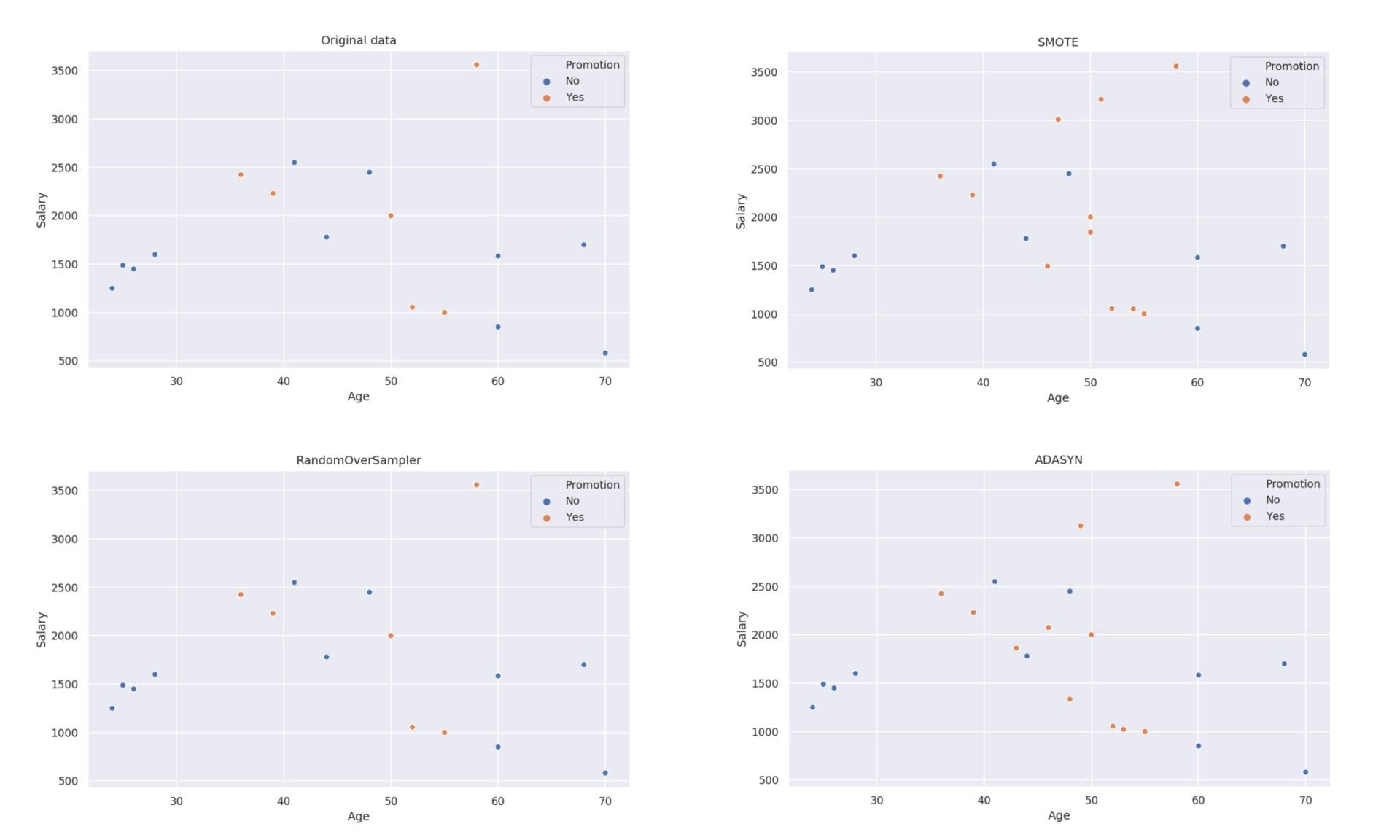
Oversampling методите увеличават представителите на по-малкото множество, като в нашия случай това е положителният клас.
Разпределението на класовете:
- Yes = 11
- No = 11
Undersampling
Undersampling е техника, при която, се намаляват случаите в класа с повече представители до такава степен, че броят им да се изравни с този в класа с по-малко представители.
- NearMiss
NearMiss е метод, който намалява броя на обектите на базата на определено правило. Алгоритъма има 3 версии, озаглавени NearMiss-1, NearMiss-2 и NearMiss-3, като коя да използва се задава чрез параметър на метода. Първата е зададена по подразбиране.
- NearMiss-1 - Премахва записите, за които средното разстояние (по kNN) до обекти от класа с по-малко представители е най-ниско.
- NearMiss-2 - Премахва тези записи, при които средното разстояние до най-далечните обекти от класа с по-малко представители е минимално.
- NearMiss-3 - Премахва записите от класа с повече представители, които имат най-малко средно разстояние до всеки обект от по-малкото множество.
nm = NearMiss()
X_res_nm, y_res_nm = nm.fit_sample(X, y.ravel())Резултат:
| Age | Salary | Promotion | |
|---|---|---|---|
| 0 | 48 | 2450 | No |
| 1 | 41 | 2550 | No |
| 2 | 24 | 1250 | No |
| 3 | 44 | 1780 | No |
| 4 | 26 | 1450 | No |
| 5 | 25 | 1488 | No |
| 6 | 55 | 1000 | Yes |
| 7 | 50 | 2000 | Yes |
| 8 | 52 | 1055 | Yes |
| 9 | 58 | 3560 | Yes |
| 10 | 36 | 2425 | Yes |
| 11 | 39 | 2230 | Yes |
- RandomUnderSampler
Методът RandomUnderSampler работи, като произволно премахва записи от по-голямото множество докато броя на представителите в класовете не се изравни. Недостатък на този метод е, че е възможно да се премахне някой обект, който всъщност да е важен и да е нужно да присъства в извадката.
rus = RandomUnderSampler()
X_res_rus, y_res_rus = rus.fit_sample(X, y.ravel())Резултат:
| Age | Salary | Promotion | |
|---|---|---|---|
| 0 | 60 | 850 | No |
| 1 | 25 | 1488 | No |
| 2 | 41 | 2550 | No |
| 3 | 68 | 1700 | No |
| 4 | 44 | 1780 | No |
| 5 | 24 | 1250 | No |
| 6 | 55 | 1000 | Yes |
| 7 | 50 | 2000 | Yes |
| 8 | 52 | 1055 | Yes |
| 9 | 58 | 3560 | Yes |
| 10 | 36 | 2425 | Yes |
| 11 | 39 | 2230 | Yes |
Обобщаваща визуализация:
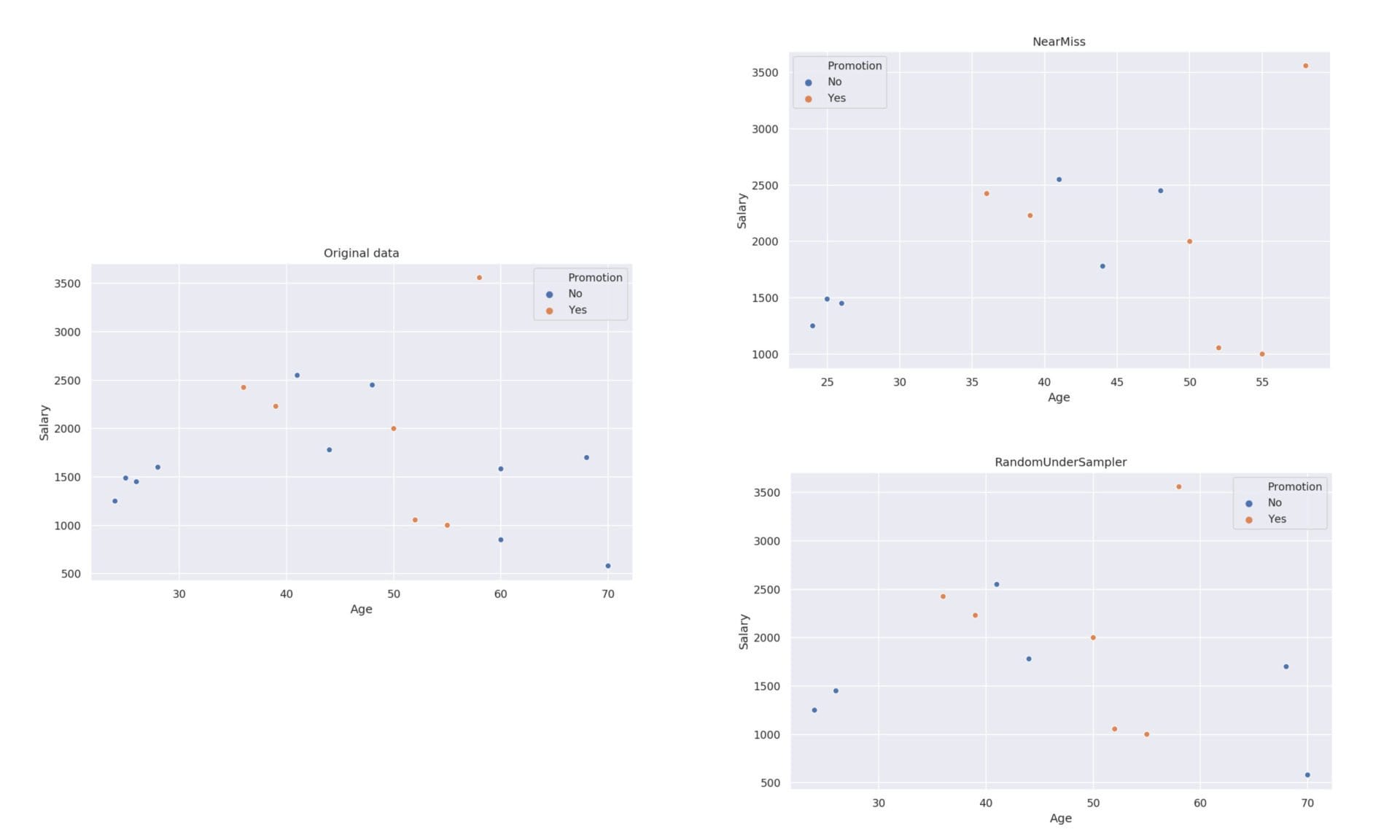
Undersampling методите намаляват представителите на по-голямото множество, като в нашия случай това е отрицателният клас.
Разпределението на класовете:
- Yes = 6
- No = 6
Коя техника да използваме?
Необходимо е да се направят множество тестове с различните методи, за да се прецени кой е най-подходящ. При прилагане на oversampling за балансиране на извадка се запазват всички оригинални записи, докато при undersampling може да се изгубят ценни данни, тъй като се премахват редове от множеството с повече представители. Може също така да се приложи и комбинация от двете техники. Като цяло възможностите са много и избор на това коя техника да използваме зависи от данните, с които разполагаме, както и от самата задача.
Искате да научите повече за машинното обучение?
Включете се в курса по машинно обучение и анализ на данни с Python.
Автор: Десислава Христова