Машинното обучение се прилага от широк кръг специалисти (бизнес анализатори, програмисти, изследователи и др.), така че понякога е трудно да преценим от къде да направим първите крачки, за да навлезем в тази така обширна област.
Могат да се използват много различни средства като например езици за програмиране, инструменти с графичен интерфейс или облачни услуги. Повече информация за тези три типични сценария за използване на машинното обучение можете да намерите в статията Machine Learning: Код, продукт или облак? Изберете вашия сценарий!
Много често хората избират език за програмиране, когато започнат да се занимават с машинно обучение, тъй като им предоставя по-големи възможности за контрол върху процеса отколкото други инструменти. За машинно обучение може да се използват доста езици за програмиране, като за тях има изградени голям набор от готови библиотеки, позволяващи лесно създаване на ML решения. На най-високо място в класациите са Python и R и хората често си задават въпроса с кой от двата да
започнат.
В тази статия ще ви разкажа за приликите и разликите между тези 2 езика и ще ви обясня за техните популярни библиотеки и пакети.
Прилики и разлики между Python и R
С единия и другия език можем да анализираме и обработваме данни, да изграждаме моделите, които са ни необходими, при това безплатно.
Какви са приликите между двата езика?
Python и R са open source езици и за тях са създадени множество пакети и библиотеки, допълващи възможностите им. Разнообразието от задачи, които могат да бъдат решени с тях, е изключително голямо и за всеки един статистически метод има създадени решения.
Съществуват среди и за двата езика, които също са open source и улесняват работата с тях. За R най-често това е RStudio, а за Python - Jupyter Notebook или Spyder.
С какво се различават Python и R?
Една от най-съществените разлики е в това, че R е функционален език за програмиране, който се използва предимно за статистически анализи. За решаването на конкретна задача е необходимо да се съчетаят подходящи функции от множеството пакети, създадени за R. Това от своя страна намалява количеството програмен код, който трябва да се напише, правейки езика достъпен за по-широк кръг специалисти.
Python е обектно-ориентиран език за програмиране с общо предназначение, но при решаване на изследователски задачи се използват предимно процедурните му възможности. По-широко се прилага, дори отвъд анализа на данни и машинното обучение (за разработка на софтуерни решения, автоматизиране на задачи, правене на тестове и т.н.) и е малко по-сложен за хора, които са далеч от програмирането.
Друга разлика е синтаксисът - на R е по-различен от този на стандартните езици за програмиране, направен е доста опростен и е подходящ за хора, които не са програмисти, докато при Python синтаксисът не се различава особено от този на останалите скриптови езици за програмиране (например JavaScript).
Ако искате да научите по-подробно за приложението на Python, можете да прочетете в следната статия: Езикът Python и неговото приложение.
Кои популярни библиотеки и пакети се използват?
В следната таблица можете да видите основните библиотеки и пакети, с които могат да се анализират и обработват данни, да се създават визуализации, както и да се изграждат модели за машинно обучение.
| Цел | R | Python |
|---|---|---|
| Анализ и обработка на данни | Tidyverse | Pandas |
| Визуализация на данни | ggplot2, Plotly, Shiny | Matplotlib, Seaborn, Bokeh, HoloViews, hvPlot |
| Машинно обучение | caret, mlr3 | Scikit-learn |
В примерите по-надолу в статията ще използваме данни от 2 извадки. Едната е за купувачи на велосипеди, а другата за банкови клиенти. Можете да ги изтеглите от тук.
За анализ и обработка на данни
При R освен вградените в езика възможности, широко приложение намира и Tidyverse колекцията от пакети за анализ и обработка на данни, докато при Python основна е библиотеката Pandas.
Tidyverse съдържа в себе си популярните пакети dplyr и tidyr, с които можем да манипулираме данни. Функциите в dplyr позволяват да селектираме, филтрираме и извършваме изчисления с данните, да сортираме и добавяме нови колони. Пакетът tidyr предоставя съхранение на данните в усъвършенствана структура tibble, разделяне и обединяване на колони, обработка на липсващи стойности и др.
Пример с R:
data %>%
select(country, yr_income) %>% # Избор на конкретни колони
group_by(country) %>% # Групиране на данните
summarise(avg_income = mean(yr_income)) %>% # Агрегиране на данните
arrange(desc(avg_income)) # Сортиране на даннитеPandas позволява използване на 2 структури - Series (едномерен масив) и DataFrame (двумерен масив) за съхранение на данните, като DataFrame е взаимствана от R. Големият набор от функции, които съдържа библиотеката, дават възможност за лесно манипулиране на данни. Можем да разделяме, свързваме и агрегираме, като операциите стават доста бързо и с малко редове код. Това прави Pandas изключително мощно средство за обработка на данни.
Същият пример с Python:
avg_income_df = (df[['country', 'yr_income']] # Избор на конкретни колони
.groupby('country', as_index = False) # Групиране на данните
.agg('mean') # Агрегиране на данните
.sort_values(['yr_income'], ascending=False) # Сортиране на данните
.rename(columns = {'yr_income': 'avg_income'})) # Преименуване на колонатаСъздадохме една и съща таблица с Python и R. Тя съдържа средния годишен доход на купувачите, разпределен по държавите, в които живеят.
| country | avg_income |
|---|---|
| United States | 91474 |
| Australia | 88791.5 |
| Canada | 84888.5 |
| United Kingdom | 65476.9 |
| Germany | 58374.8 |
| France | 52845.1 |
Таблицата е сортирана в низходящ ред по средния размер на дохода.
Визуализация на данни
Основният пакет за R, който е предназначен за визуализация на данни, е ggplot2. Той е базиран на концепциите от книгата Граматика на Графиките от Л. Уилкинсън (The Grammar of Graphics by L. Wilkinson) и благодарение на множеството функции, които съдържа, можем по елегантен начин да визуализираме числови и категорийни данни.
Част е от tidyverse колекцията и предоставя практически неограничени възможности при визуализация, тъй като има много видове диаграми за представяне на данните.
Пример с R:
data %>% ggplot(aes(x=age, y=yr_income)) + # Избор на колони
geom_point(color= 'blue', alpha = 0.3) + # Настройки на диаграмата
ggtitle('Age vs Yearly Income') + # Промяна на заглавие
xlab('Age') + # Задаване на етикет за данните по оста х
ylab('Yearly Income') # Задаване на етикет за данните по оста у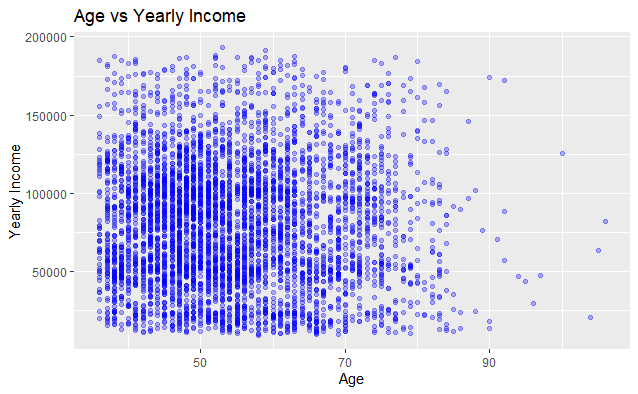
При Python най-често се използва библиотеката Matplotlib за създаване на визуализации. Тя е изключително мощно средство, което позволява изграждане на висококачествени визуализации. В практиката се използва заедно със Seaborn, която разширява нейните възможности и позволява с по-малко редове код да се изграждат естетически красиви визуализации.
Същият пример с Python:
# Създаване на диаграма на разсейването
plt.scatter(data=df, x ='age', y = 'yr_income',
color ='b', alpha = 0.3)
# Задаване на заглавие на диаграмата
plt.title('Age vs Yearly Income')
# Задаване на етикет за данните по оста х
plt.xlabel('Age')
# Задаване на етикет за данните по оста у
plt.ylabel('Yearly Income')
# Показване на визуализацията
plt.show()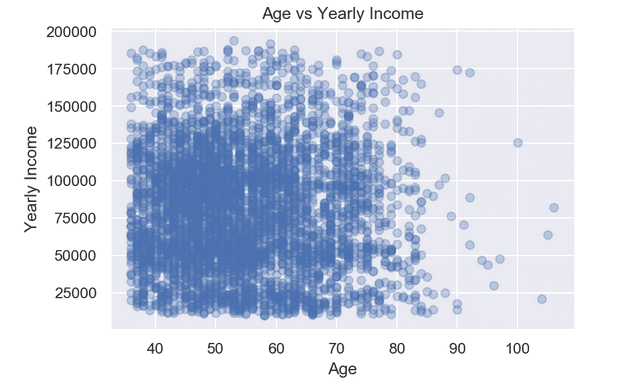
С двата езика създадохме една и съща диаграма на разсейването, показваща връзката между 2 променливи - възрастта и годишния доход на купувачите.
Python също има библиотека с наименование ggplot, която е базирана на тази на R. Тя дава възможност на хора, работели предимно с R, да визуализират данни и с Python.
Двата езика имат и различни библиотеки за изграждане на интерактивни визуализации. При Python такива са Bokeh, HoloViews, hvPlot и др., а при R се използват предимно Plotly и Shiny.
Ако искате да научите повече за интерактивните визуализации с Python, можете да прочетете в статията Machine Learning: Интерактивни визуализации с Python.
Машинно обучение
В R има универсални интерфейси към множество методи за машинно обучение (caret, mlr3), както и директни модели (lm(), knn()) под формата на функции. Универсалните интерфейси улесняват прототипирането на задачите и избора на конкретен модел, а директните дават по-голяма гъвкавост и контрол върху процеса на решаване на задачата.
Caret и mlr3 предоставят възможности за:
- разделяне на данните на обучаваща и тестова извадка
- предварителна обработка на данните (справяне с липсващи стойности, мащабиране на данни, кодиране на категорийни променливи)
- избор на най-важните за модела променливи
- създаване, оценка и оптимизация на модели
С двата пакета могат да се решават задачи с контролна извадка (supervised learning) - класификация и регресия. За такива без контролна извадка (unsupervised learning) - клъстеризация, метод на главните компоненти (PCA) и др., е необходимо да се използват други пакети като stats или factoextra например.
Пример с R:
# Разделяне на данните на обучаваща и тестова извадка
set.seed(17)
bank_data.split <- initial_split(bank_data, prop = 0.7, strata = 'y')
bank_data.train <- training(bank_data.split)
bank_data.test <- testing(bank_data.split)
# Създаване на KNN модел чрез caret
bank_data.knn <-
caret::train(
y ~ .,
preProcess = c('scale','center'),
data = bank_data.train,
method='knn'
)
# Тест на модела
knn_pred <- predict(bank_data.knn, newdata = bank_data.test)
# Преглед на резултати в матрица на неточностите
cm <- confusionMatrix(factor(knn_pred),
factor(bank_data.test$y),
dnn = c('Predicted', 'Actual'))
ggplot(as.data.frame(cm$table),
aes(Predicted,
sort(Actual, decreasing = T),
fill= Freq)) +
geom_tile() +
geom_text(
aes(label=Freq)
) +
scale_fill_gradient(low='white', high='blue') +
ggtitle('KNN confusion matrix') +
labs(x = 'Actual', y = 'Predicted') +
scale_x_discrete(labels=c('No', 'Yes')) +
scale_y_discrete(labels=c('No', 'Yes'))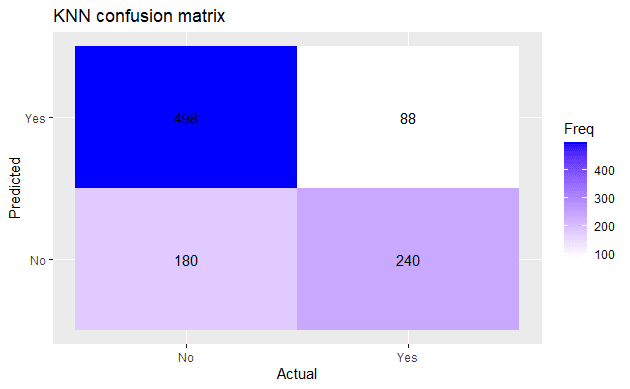
Общата точност на модела е 73%.
При Python за машинно обучение най-популярна и често използвана е библиотеката Scikit-learn. При нея е удобно това, че всичко е събрано на едно място. Тя предоставя голям набор от възможности по време на всеки етап от изграждането на ML решения. Scikit-learn съдържа много алгоритми за статистическо обучение с или без контролна извадка, откриване на оптимални параметри и оценка на моделите.
Същият пример с Python:
# Разделяне на данните - 70% за обучение и 30% за тест
X=df.drop(['y'], axis='columns')
Y=df['y']
X_train, X_test, y_train, y_test = train_test_split(X,
Y,
test_size=0.3,
random_state=17)
# Стандартизиране на данните
scaling = StandardScaler().fit(X_train)
X_train_ss = scaling.transform(X_train)
X_test_ss = scaling.transform(X_test)
# Създаване на KNN модел
knn = KNeighborsClassifier()
knn.fit(X_train_ss, y_train)
knn.predict(X_test_ss)
# Преглед на резултати в матрица на неточностите
plot_confusion_matrix(knn, X_test_ss, y_test,
display_labels=['No','Yes'],
values_format='.0f',
cmap=plt.cm.Blues)
plt.grid(False)
plt.title('KNN Confusion Matrix')
plt.tight_layout()
plt.show()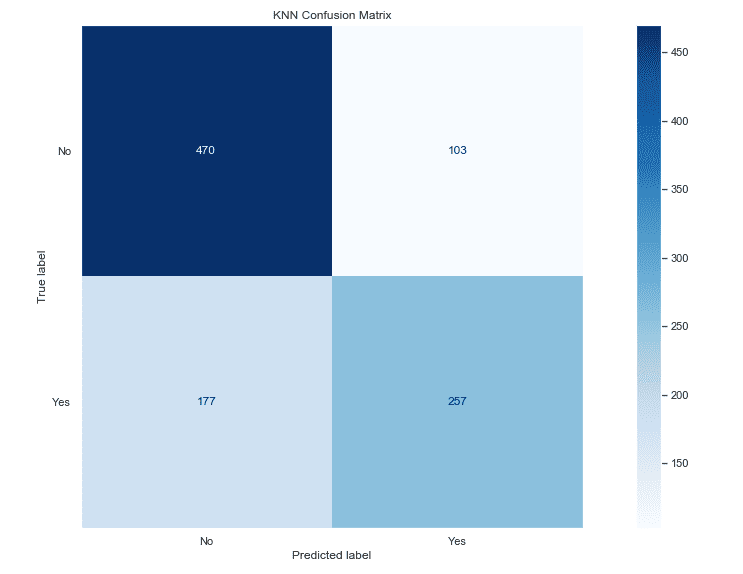
Общата точност на модела е 0.72%.
С двата езика изградихме модел за машинно обучение, който използва алгоритъма k най-близки съседи. Има съвсем минимална разлика в получената обща точност и в резултатите при матриците на неточностите на двата модела.
Кой език да изберем?
Двата езика имат еднакви възможности и с тях могат да се постигнат едни и същи резултати. Изборът на конкретен език не зависи от задачите, които ще решаваме с него, а това до колко е естествено за нас да програмираме. Дали ще се спрем на Python или R опира до това до каква степен се занимаваме с програмиране.
За хора, които са специалисти в конкретна област и не им се е налагало да програмират, R e по-удачното решение. Обаче ако човек е насочен към ИТ сферата и иска например в приложение да вгради аналитична част, Python ще бъде по-подходящото решение. Той позволява в една олекотена форма да се прототипират задачи. Това, което се прави на Python, после по-лесно може да се пренапише на друг език, отколкото ако е първоначално написано на R.
Автор: Десислава Христова