Попадали ли сте в ситуация, в която имате база данни с множество еднотипни продукти, предварително разделени в класове. При добавяне на нов продукт какви са критериите, по които определяте точно в кой клас трябва да попадне той?
Тук на помощ идва класификацията. Тя е това, което ще придаде ред и структура, като групира по сходни характеристики. Идеята е да се намерят връзки между данните, които ни позволяват да направим разграничение между самите обекти. За да можем успешно да направим класификация, трябва да преценим кой би бил най-правилният метод за тази цел.
Съществуват най-различни начини за разпределяне на обекти в класове – Decision Tree, Random Forest, SVM (Support Vector Machines), kNN (k-nearest neighbors) и други. Кой метод да използваме определяме след задълбочен анализ на данните и множество тестове. Критерии за най-правилния метод са например каква е точността, колко време отнема за обучение, сложността на модела и други.
В тази статия ще разгледаме алгоритъма kNN и ще видим как действа той на практика чрез пример, в който ще разпределим продукти в класове.
Какво представлява kNN?
kNN е популярен алгоритъм за машинно обучение, който е предназначен за решаване на задачи, свързани с класификация на обекти или регресия. Използва се при необходимост от определяне кой обект с кои други си прилича (например групиране на клиенти със сходни характеристики).
kNN спада към тези алгоритми, които са с контролирано обучение (supervised), т.е. имаме набор от характеристики и целева променлива с известни стойности. На базата на тях обучаваме модела, като разделяме данните. Едната извадка се използва за обучение на модела, а другата за тест.
- При класификация – един обект спада към класа, който е най-често срещан сред най-близките му k-съседи
- При регресия – използва се за определяне на неизвестна характеристика на обект като се взима стойността, която най-много се наблюдава сред най-близките му k-съседи.
Какво е необходимо за класификация на обектите чрез kNN?
За прилагането на алгоритъма kNN е нужно да:
- Изчислим разстоянията между обектите от обучаващата извадка
- Изберем k обекти от обучаващата извадка, до които разстоянието е минимално
- Поставим обекта в класа, който най-често се среща сред най-близките му k-съседи.
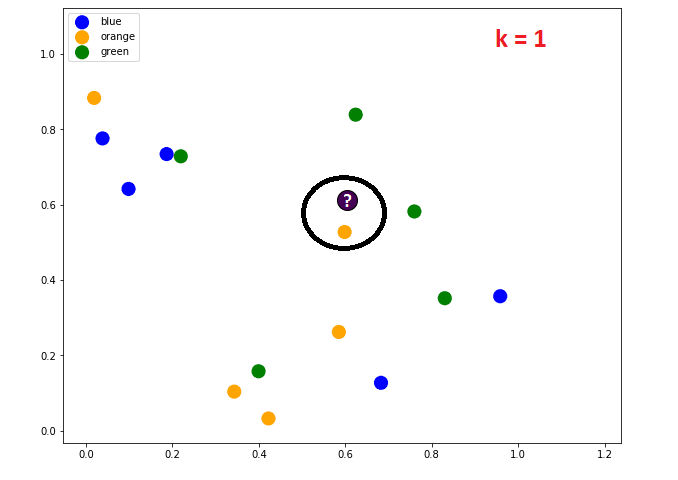
На изображението ясно се вижда, че при k=1 обектът ще е от класа на най-близкия му съсед – оранжевия.
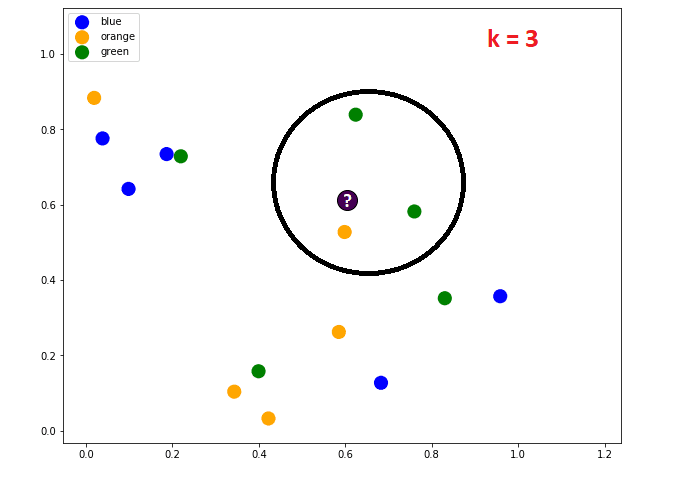
При k=3 гледаме трите най-близки съседи и тъй като 2 от тях са от зеления клас, а един е от оранжевия, некласифицираният обект ще бъде от зеления клас.
Качество на модела
От какво зависи качеството?
- броя съседи
- метриката за определяне на разстоянието (евклидово, косинусно, на Минковски и др.), като при повечето метрики е необходимо мащабиране на характеристиките (напр. заплата 100000, възраст до 100)
- тегло на съседите
Начини за проверка на качеството
- разделяне на извадката на обучаваща (60-80%) и тестова (40-20%) и изчисляване на процент правилни отговори (най-простата метрика)
- кръстосан контрол (cross validation) – алгоритъмът се обучава k-пъти и получените резултати се осредняват. Дава по-добри резултати, но изисква повече изчисления.
Практически пример за разпределяне на продукти в класове чрез kNN
В нашият пример ще използваме данни за продукти от онлайн магазин, като имаме следните колони:
- uniq_id – уникалният идентификатор на продукта
- product_name – наименованието на продукта
- manufacturer – фирмата, която е изработила продукта
- price – единичната цена
- number_available_in_stock – колко броя има на склад
- number_of_reviews – брой мнения от клиентите
- number_of_answered_questions – брой отговорени въпроси относно продукта
- average_review_rating – средна оценка на продукта
- popularity – колко е популярен сред клиентите
На базата на тези данни, когато има нов запис, ще е необходимо да можем да преценим колко популярен е продуктът, като чрез алгоритъма kNN го класифицираме в някоя от трите категории за популярност – ниска, средна или висока.
Стъпка 1: Импорт на библиотеки и зареждане на данните
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import seaborn as sns
sns.set()
import matplotlib.pyplot as pltdf = pd.read_csv('./datasets/products-final.csv', sep=',')
df.head()Резултат:
| No | uniq_id | product_name | manufacturer | price | number_available_in_stock | number_of_reviews | number_of_answered_questions | average_review_rating | popularity |
|---|---|---|---|---|---|---|---|---|---|
| 0 | eac7efa5dbd3d667f26eb3d3ab504464 | Hornby 2014 Catalogue | Hornby | 39.2 | 60 | 3 | 1 | 3 | medium |
| 1 | b17540ef7e86e461d37f3ae58b7b72ac | FunkyBuys® Large Christmas Holiday Express Fe... | FunkyBuys | 74.5 | 6 | 27 | 1 | 4 | high |
| 2 | 348f344247b0c1a935b1223072ef9d8a | CLASSIC TOY TRAIN SET TRACK CARRIAGES LIGHT EN... | ccf | 1.4 | 2 | 3 | 2 | 0 | low |
| 3 | e12b92dbb8eaee78b22965d2a9bbbd9f | HORNBY Coach R4410A BR Hawksworth Corridor 3rd | Hornby | 26.6 | 44 | 28 | 2 | 0 | low |
| 4 | e33a9adeed5f36840ccc227db4682a36 | Hornby 00 Gauge 0-4-0 Gildenlow Salt Co. Steam... | Hornby | 80.1 | 37 | 2 | 2 | 3 | medium |
Стъпка 2: LabelEncoder
Използваме LabelEncoder, за да преобразуваме качествените данни в количествени.
from sklearn.preprocessing import LabelEncoderlabelencoder=LabelEncoder()
for column in df.columns:
df[column] = labelencoder.fit_transform(df[column])
df.head()Резултат:
| No | uniq_id | product_name | manufacturer | price | number_available_in_stock | number_of_reviews | number_of_answered_questions | average_review_rating | popularity |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 193 | 84 | 21 | 70 | 54 | 3 | 0 | 3 | 2 |
| 1 | 143 | 52 | 17 | 133 | 6 | 27 | 0 | 4 | 0 |
| 2 | 47 | 24 | 65 | 3 | 2 | 3 | 1 | 0 | 1 |
| 3 | 182 | 59 | 21 | 44 | 39 | 28 | 1 | 0 | 1 |
| 4 | 185 | 67 | 21 | 140 | 32 | 2 | 1 | 3 | 2 |
Стъпка 3: Разделяне на данните на обучаваща и тестова извадка
Заделяме 70% от данните за обучението и 30% за тест.
from sklearn.model_selection import train_test_splitX=df.drop(['popularity'], axis=1)
Y=df['popularity']
X_train, X_test, y_train, y_test = train_test_split(X,
Y,
test_size=0.3,
random_state=17)Стъпка 4: Обучение на модела
from sklearn.neighbors import KNeighborsClassifierknn = KNeighborsClassifier(n_neighbors=10)%%time
knn.fit(X_train, y_train)Стъпка 5: Проверка на качеството на модела
from sklearn.metrics import accuracy_scoreknn_pred = knn.predict(X_test)
accuracy_score(y_test, knn_pred)Резултат: 0.3333333333333333
В 33% от случаите моделът разпределя правилно продуктите в класовете.
Стъпка 6: Избор на оптимални параметри
from sklearn.model_selection import GridSearchCV, cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScalerknn_pipe = Pipeline([('scaler', StandardScaler()),
('knn', KNeighborsClassifier(n_jobs=3))])
knn_params = {'knn__n_neighbors':range(1,10)}knn_grid = GridSearchCV(knn_pipe, knn_params,cv=5, n_jobs=3, verbose=True)%%time
knn_grid.fit(X_train, y_train)knn_grid.best_params_, knn_grid.best_score_Резултат:
({‘knn__n_neighbors’: 4}, 0.8)
accuracy_score(y_test, knn_grid.predict(X_test))Резултат: 0.746031746031746
С оптималните параметри, в 75% от случаите моделът разпределя правилно продуктите в класовете.
Цялостния пример можете да свалите от тук.
Можете да използвате Jupyter Notebook или друг подобен инструмент, за да го изпълните.
Защо е важен този метод и в кои области е полезен?
kNN е алгоритъм, който е много лесен за разбиране и работи страхотно в практиката. Като предимство можем да кажем, че той е един от добре изучените методи и се ползва в много области (иконометрика, статистика и др.). За KNN съществуват важни теореми, съгласно които този метод е оптимален за класификация на безкрайни извадки. Може би едни от най-важните недостатъци, които има kNN, са това, че трябва да намерим оптималния брой съседи и че алгоритъмът не работи толкова добре, когато расте броят на променливите в данните. Колкото по-малко са, толкова по-точен е.
Искате да научите повече за машинното обучение?
Включете се в курса по машинно обучение и анализ на данни с python.
Автор: Десислава Христова