Забелязах, че като слушам една песен, след нея винаги пускам следваща и след това пак следваща. Това ме подтикна да проверя дали има някаква закономерност в музиката, която си пускам, дали слушането на една песен провокира слушането на друга определена.
Оказва се, че има определена зависимост и тя може лесно да се представи под формата на асоциативни правила.
Как изглеждат асоциативните правила?
ако {списък от елементи} => {следствие}
Те се състоят от списък от елементи (antecedent), който води до някакво следствие (consequent).
Алгоритми за решаване на задачи, свързани с асоциативни правила, са например Apriori и FP-Growth.
Също така на базата на асоциативни правила може да се правят и препоръки за подходящи песни при слушане на някоя конкретна.
В тази статия ще разгледаме практически пример, в който ще открием зависимост между песни, слушани в Spotify, чрез алгоритъма FP-Growth, след което ще генерираме асоциативни правила и ще създадем собствена функция за препоръки.
Как работи алгоритъмът FP-Growth?
FP-Growth е алгоритъм, с който можем да открием обекти, които често се срещат заедно. При него, както при Apriori, се задава предварително минимален праг на честота на срещане, но разликата е в това, че данните не се сканират всеки път, а се преминава през тях само 2 пъти. Това прави алгоритъма доста по-бърз от Apriori.
Трябва да преминем през няколко стъпки:
- Изчисляване на честота на срещане за всеки от елементите след сканиране на входните данни
- Сортиране на данните в низходящ ред и проверка дали се покрива минималния зададен праг
- Създаване таблица с транзакции и списък от елементите, като те са сортирани в низходящ ред според честотата на срещане
- Изграждане на FP дърво (FP tree)
- Откриване на чести комбинации от елементи
Например в следната таблица можете да видите 9 транзакции, в които участват определени хранителни продукти.
| TP | бира (Б) | месо (M) | хляб (X) | вода (В) | яйца (Я) | круши (К) |
|---|---|---|---|---|---|---|
| TP1 | 0 | 1 | 1 | 0 | 1 | 0 |
| TP2 | 0 | 1 | 0 | 1 | 0 | 0 |
| TP3 | 1 | 1 | 0 | 0 | 0 | 0 |
| TP4 | 0 | 1 | 1 | 1 | 0 | 0 |
| TP5 | 1 | 0 | 1 | 0 | 0 | 0 |
| TP6 | 1 | 0 | 0 | 0 | 0 | 1 |
| TP7 | 1 | 1 | 1 | 0 | 0 | 0 |
| TP8 | 1 | 1 | 1 | 0 | 1 | 0 |
| TP9 | 1 | 1 | 1 | 0 | 0 | 0 |
Ако приемем, че сме задали като минимален праг 0.2, алгоритъмът ще премахне тези продукти, които се срещат в по-малко от 20% от всички транзакции.
Изчисляване на честота на срещане за всеки елемент и подреждане в низходящ ред
| Елемент | Честота на срещане (брой) | Честота на срещане (%) |
|---|---|---|
| М | 7 | 0.777778 |
| Б | 6 | 0.666667 |
| Х | 6 | 0.666667 |
| Я | 2 | 0.222222 |
| В | 2 | 0.222222 |
| К | 1 | 0.111111 |
С най-висока честота на срещане е месото 0.78, а с най-ниска са крушите 0.11.
Проверка дали се покрива минималния зададен праг
Ако честотата на срещане на някой от елементите е по-малка от минималния праг, той се отхвърля. Алгоритъмът работи на принципа, че ако един продукт е рядко срещан, то комбинациите с него също са.
Тъй като крушите се срещат в 11% от транзакциите и попадат под праговата стойност, те ще бъдат премахнати от по-нататъшните разглеждания.
Създаване таблица с транзакции и списък от елементи
| ТР | Списък от елементи |
|---|---|
| ТР1 | М, Х, Я |
| ТР2 | М, В |
| ТР3 | М, Б |
| ТР4 | М, Х, В |
| ТР5 | Б, Х |
| ТР6 | Б |
| ТР7 | М, Б, Х |
| ТР8 | М, Б, Х, Я |
| ТР5 | М, Б, Х |
След като имаме подредените елементи, можем да преминем към изграждането на FP дърво.
Изграждане на FP дърво
От началния елемент на дървото (null) се спускат пътища за всяка една транзакция и се задава брояч със стойност 1 за всеки от възлите. Там, където има съвпадение на елементите при създаване на пътищата, броячът на съответния елемент се увеличава с единица. Колкото повече се припокриват пътищата, толкова повече данните се компресират.
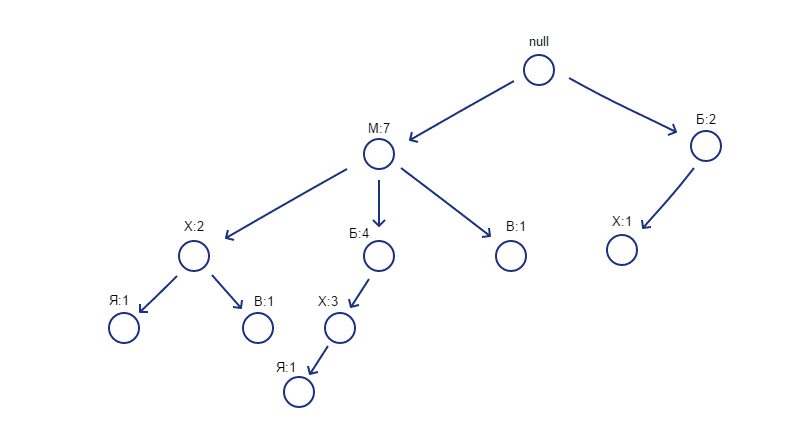
Следната визуализация представя финалния вид на FP дървото за нашия пример. Можете да видите, че лявата страна на дървото има доста повече разклонения отколкото дясната.
От тук нататък алгоритъмът открива чести комбинации от елементи.
Таблица с чести комбинации
За създаване на таблицата се преминава през дървото отдолу-нагоре и се вписват елементите във възходящ ред според честотата на срещане. Пропускат се тези елементи, до които няма конкретни пътища. В нашия случай това е месото.
Първо се описват конкретните пътища до всеки от елементите и като брояч се поставя стойността, съответстваща на елемента в края на пътя. След това се създава условно FP дърво, при което се сумират броячите за всеки от елементите. В тази колона отново се прави проверка дали е спазен минималния праг. Накрая се извличат честите комбинации. Ако комбинацията съдържа повече от 2 елемента, както е в случая на {М,Б,Х:3} например, се взима най-малката от стойностите на броячите.
В следната таблица можете да видите откритите чести комбинации от елементи и тяхната честота на срещане.
| Комбинации от елементи | Честота на срещане (брой) | Честота на срещане (%) |
|---|---|---|
| {M,X} | 5 | 0.555556 |
| {M,Б} | 4 | 0.444444 |
| {Б,Х} | 4 | 0.444444 |
| {M,Б,Х} | 3 | 0.333333 |
| {X,Я} | 2 | 0.222222 |
| {M,Я} | 2 | 0.222222 |
| {M,X,Я} | 2 | 0.222222 |
| {M,В} | 2 | 0.222222 |
Критерии за оценка
За да разберем колко добри са асоциациите, можем да използваме някои метрики за оценка като например поддръжка (support, coverage), достоверност (confidence, accuracy), подемна сила (lift), натиск (leverage) и убеденост (conviction).
support(A\rightarrow T) = P(A\cup T)confidence(A\rightarrow T) = \frac{P(A\cup T)}{P(A)} = \frac{support(A\rightarrow T)}{support(A)}lift(A\rightarrow T) = \frac{conf(A \rightarrow T)}{support(T)}=\frac{support(A \rightarrow T)}{support(A)\times support(T)}leverage(A\rightarrow C) = {support}(A\rightarrow C) - {support}(A) \times{support}(C) = P(X \cap Y) - P(X) \times P(Y)conviction(A\rightarrow C) = \frac{1 - {support}(C)}{1 - {confidence}(A\rightarrow C)} = \frac{P(X) \times P(\overline Y )}{P(X \cap \overline Y)}Формулите са обяснени в следната статия: Machine Learning: Кой продукт с кои други се купува? (Асоциативни правила)
Практически пример
Извадката, която ще използваме, съдържа данни за песните, които съм слушала в Spotify само през 2020-та година. Тя съдържа 347 реда, съответстващи на определени дни от годината, в които съм слушала музика в Spotify. Песните са 980 на брой и за всяка е създадена отделна колона.
Можете да изтеглите файла с първоначалната обработка на данните от тук.
5 случайно избрани редове и колони от данните изглеждат по следния начин:
| Heffron Drive - Could You Be Home (Ras Remix) | K/DA - THE BADDEST | Jacob Lee - Ghost | Dan Talevski - Blackout | James Arthur - Quite Miss Home | |
|---|---|---|---|---|---|
| 221 | 0 | 0 | 0 | 0 | 0 |
| 149 | 0 | 0 | 0 | 0 | 1 |
| 333 | 0 | 0 | 0 | 0 | 0 |
| 325 | 0 | 0 | 0 | 0 | 0 |
| 184 | 0 | 0 | 0 | 0 | 0 |
Там където песента е слушана в конкретния ден се отбелязва с 1, а в противен случай стойността е 0.
Със стълбовидна диаграма можем да видим кои са 10-те най-слушани песни според броя дни.
# Създаване на речник с песни и брой дни, в които са слушани
listens_dict = {'Songs': df.columns, 'Days': df.sum()}
# Създаване на нов DataFrame от речника
df_listens = pd.DataFrame(listens_dict)
# Сортиране на данните по брой дни
df_listens = df_listens.sort_values(by='Days', ascending=False).reset_index(drop=True)
# Намиране на 10-те най-слушани песни по брой дни
top_10 = df_listens.nlargest(10, 'Days')
# Изграждане на стълбовидна диаграма
fig = px.bar(top_10, x='Songs', y='Days', title='Top 10 songs by days listened to')
# Показване на визуализацията
fig.show()Песента, която е слушана най-много, е CVBZ – 2 Gone, в 75 дни от годината, а на 10-то място е James TW – You & Me, слушана в 53 дни от годината.
Използване на алгоритъма FP-Growth и генериране на асоциативни правила
Ше използваме функцията fpgrowth(), предоставена от библиотеката mlxtend на Python и ще зададем минимален праг 0.08, за да използва само тези песни, които са слушани в над 8% от всички случаи. След това ще използваме функцията association_rules(), за да генерираме асоциативни правила.
# Прилагане на алгоритъма FP-Growth
df_fpgrowth = fpgrowth(df, min_support=0.08, use_colnames=True, verbose=1)
# Генериране на асоциативни правила
rules = association_rules(df_fpgrowth, metric='support', min_threshold=0.08)
# Сортиране на данните в низходящ ред по метриката достоверност
rules.sort_values('confidence', ascending=False)Алгоритъмът е генерирал 1208 на брой правила.
| antecedents | consequents | antecedent support | consequent support | support | confidence | lift | leverage | conviction | antecedent_len | |
|---|---|---|---|---|---|---|---|---|---|---|
| 559 | Shawn Hook - So Close | Isak Danielson - Always, James TW - Happy For Me | 0.152738 | 0.0979827 | 0.0835735 | 0.54717 | 5.58435 | 0.0686078 | 1.99195 | 1 |
| 365 | Isak Danielson - I Don't Need Your Love, James TW - You & Me | Isak Danielson - Always | 0.092219 | 0.172911 | 0.0864553 | 0.9375 | 5.42188 | 0.0705097 | 13.2334 | 2 |
| 1180 | Heffron Drive - Not Alone | Ariana Grande - Break Free, Chase Atlantic - OUT THE ROOF | 0.135447 | 0.092219 | 0.0835735 | 0.617021 | 6.69082 | 0.0710827 | 2.37032 | 1 |
| 741 | Isak Danielson - Religion, Shawn Hook - So Close | CVBZ - 2 Gone, CVBZ - Feel Like You're Mine | 0.0951009 | 0.170029 | 0.0806916 | 0.848485 | 4.99024 | 0.0645218 | 5.47781 | 2 |
| 998 | Dan Talevski - Touch the Sky, CVBZ - 2 Gone, Jacob Lee - Heartstrings | Isak Danielson - Always | 0.092219 | 0.172911 | 0.0806916 | 0.875 | 5.06042 | 0.064746 | 6.61671 | 3 |
В таблицата можете да видите 5 случайно избрани правила, както и различните метрики за оценка. Например на ред 1180 в 8% от всички случаи е слушана песента Heffron Drive – Not Alone и при 62% от тях това е довело до слушане на песните Ariana Grande – Break Free и Chase Atlantic – OUT THE ROOF.
Визуализация на правилата
С помощта на визуализации можем нагледно да представим по-важните асоциативни правила. Ще филтрираме данните така, че да останат само тези редове, при които достоверността е над 0.90, т.е. при които в над 90% от случаите слушането на определени песни в съответния ден е довело до слушане на други конкретни песни.
Ще изградим диаграма на разсейването, за да представим асоциативните правила.
# Изграждане на диаграма на разсейването
fig = px.scatter(rules_filtered,
x='support',
y='lift',
color='confidence',
color_continuous_scale='reds',
hover_data=['support', 'lift', 'confidence', 'antecedents', 'consequents'])
# Показване на визуализацията
fig.show()Визуализацията показва връзката между метриките поддръжка и подемна сила, а цветът на точките се определя в зависимост от стойността на метриката достоверност. Колкото по-висока е тя, толкова по-червен е цветът. Тази диаграма на разсейването позволява по-лесно да открием кои са правилата с най-висока достоверност.
Например някои от тях са:
{Isak Danielson – Religion, CVBz – 2 Gone} => {Isak Danielson – Always}
{CVBZ – Feel Like You\’re Mine, CVBZ – River} => {CVBZ – 2 Gone}
{Dan Talevski – Touch the Sky, Jacob Lee – Heartstrings, Isak Danielson – Always} => {CVBZ – 2 Gone}
На следващата визуализация можете да видите различните песни и броя връзки между тях.
С най-голям брой връзки е песента CVBZ – 2 Gone (47). Също с голям брой са песните Isak Danielson – Always (39), Isak Danielson – Religion (20) и CVBZ – Feel Like You\’re Mine (17).
Кода за тази графика можете да намерите в цялостното решение на задачата.
Създаване на функция за препоръки на песни
С данните от последната визуализация можем да създадем собствена функция за препоръка на песни, която да открива съседи на песента, която сме задали, и да препоръчва други подходящи песни според броя връзки.
def recommend_songs(song):
# Създаване на речник за препоръките
recs = {}
# Откриване на съседите за всяка песен
for i in G.neighbors(song):
for j in G.neighbors(i):
if j == song or j.find(song) != -1:
continue
recs.update({j: [i]})
# Създаване на списъци за песните и броя връзки
songs=[]
connections=[]
# Добавяне на елементи в списъците
for key, values in recs.items():
songs.append(key)
connections.append(G.degree(key))
# Създаване на DataFrame с резултатите
result = pd.DataFrame({'Recommended Songs': songs, 'Number of Connections':np.array(connections)})
result.sort_values(by='Number of Connections', inplace=True, ascending=False)
return resultЩе тестваме функцията как работи, като ѝ подадем песента Isak Danielson – Always и видим кои песни ще препоръча да слушаме.
recommendations = recommend_songs('Isak Danielson - Always')В следната таблица можете да видите 5-те най-препоръчвани песни, получени като резултат от функцията.
| Recommended Songs | Number of Connections | |
|---|---|---|
| 1 | CVBZ - 2 Gone | 47 |
| 6 | Isak Danielson - Religion | 20 |
| 5 | CVBZ - Feel Like You're Mine | 17 |
| 7 | Isak Danielson - I Don't Need Your Love | 9 |
| 9 | SVRCINA - Astronomical | 9 |
Почти всичките са бавни песни и доста сходни по звучене. С най-голям брой връзки е песента CVBZ – 2 Gone (47).
Извод
Генерираните асоциативни правила ни позволяват да добием представа кои песни слушаме една след друга в определени дни. Благодарение на получените резултати резултати нашата функция за препоръка на песни ни прави подходящи предложения,
които след това можем да добавим в нов плейлист.
Разбира се, използването на асоциативни правила, е само един от начините за правене на препоръки. Има и много други като например колаборативно филтриране (collaborative filtering) или филтриране на база съдържание (content-based filtering),
с които бихме могли да правим още по-точни предложения.
Искате да научите повече за Python?
Включете се в курса по програмиране на Python.
Автор: Десислава Христова