Изграждането на класификационен модел е една от най-популярните задачи в сферата на машинното обучение. При нея целта е да се разпределят обекти в точно определени предварително зададени класове, като ако броят им е 2, то тогава имаме случай на бинарна класификация, а ако е 3 или повече, задачата е многокласова. В практиката класификационните модели са изключително полезни при решаване на различни бизнес задачи.
След създаване на модела е важно да разберем дали той работи оптимално при постъпване на нови данни. За тази цел са необходими множество тестове и преглед на различните показатели, които определят колко добре се справя той.
В тази статия ще ви запозная с някои от основните метрики за оценка на модели за класификация в контекста на конкретен пример.
Извадката, която ще използваме съдържа 10 000 записа и 13 колони с данни за клиенти на банка (пол, баланс по сметката, заплата и др.). Целта е да се разбере на базата на известните характеристики дали даден клиент ще се откаже от услугите на банката или не. При изграждане на модела за класификация ще бъдат използвани 4 метода - логистична регресия (Logistic Regression), случайна гора (Random Forest), k най-близки съседи (kNN) и метод на опорните вектори (SVC).
Фокусът на примера е върху метриките за оценка на класификационния модел. Поради тази причина данните са предварително изчистени, т.е. премахнати са ненужни характеристики, кодирани са категорийните променливи, премахнати са отличителни (екстремни) стойности и т.н. Ако искате да научите повече конкретно за някои стъпки, които се предприемат при етапа на предварителна подготовка на данните, можете да прочетете в съответните статии:
- Machine Learning: Как да обработим липсващи стойности при подготовката на данни за анализ?
- Machine Learning: Как да се справим с отличителни стойности (outliers)?
- Machine Learning: Защо е важно данните да са мащабирани?
- Machine Learning: Силата на визуализацията на данни. Коя графика какво ни показва?
- Machine Learning: Интерактивни визуализации с Python
- Machine Learning: Какво означава извадката да не е балансирана?
Примера, който ще разгледаме по-надолу, можете да изтеглите от тук.
Как правилно да оценим класификационни модели?
До колко е добър един модел за класификация можем да определим от стойностите на съответните метрики за оценка на качеството. Не е достатъчно да се гледа само една от тях. Трябва да се вземат под внимание няколко метрики, като избора на това кои са по-важни е в зависимост от самата задача и съответните цели на бизнеса.
Какво означава това можем да разгледаме на базата на прост пример с класификатор на имейли като спам или полезно писмо. Кое е по-важно за нас - да не допускаме в пощата никакви спам писма, но тогава има вероятност и част от полезните да бъдат определени като спам или да не пропускаме полезни имейли, но процент от спам съобщенията да попаднат във входящата кутия? В този случай не трябва да се гледа само цялостната точност на класификатора, а да се следят и другите метрики - прецизност и пълнота, които са в противовес и когато едното се увеличава, другото намалява. Необходимо е в зависимост от ситуацията да се прецени кое е по-важно и съответно стойността на коя метрика е от по-голямо значение при оценка на качеството на модела.
Матрица на неточностите (Confusion Matrix)
Това е един от най-популярните начини за оценка на качеството на модел за класификация. Представлява матрица с размер N x N, където N е броят класове на целевата променлива.
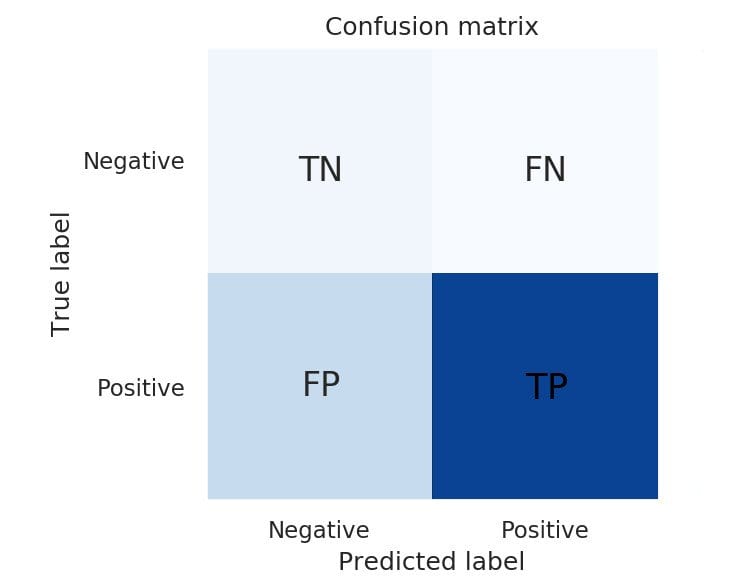
При матрицата на неточностите се съпоставят определените от класификатора и действителните стойности по 4 метрики – True Positive, False Positive, False Negative и True Negative.
- True Positive (TP) - обекти, класифицирани като положителни и в действителност са в положителния клас
- False Positive (FP) или Type I Error - обекти, класифицирани като положителни, но в действителност са в отрицателния клас
- True Negative (TN) - обекти, класифицирани като отрицателни и в действителност са в отрицателния клас
- False Negative (FN) или Type II Error - обекти, класифицирани като отрицателни, но в действителност са в положителния клас
# Създаване на списък с класификаторите
classifiers = [logreg, rf, knn, svc]
# Графично изобразяване на матриците на неточностите
fig, axes = plt.subplots(2,2, figsize=(15,10))
for cf, ax in zip(classifiers, axes.flatten()):
plot_confusion_matrix(cf, X_test_ss, y_test,
display_labels=['No','Yes'],
ax=ax,
values_format='.0f',
cmap=plt.cm.Blues)
ax.grid(False)
ax.title.set_text(type(cf).__name__)
plt.tight_layout()
plt.show()Резултат:
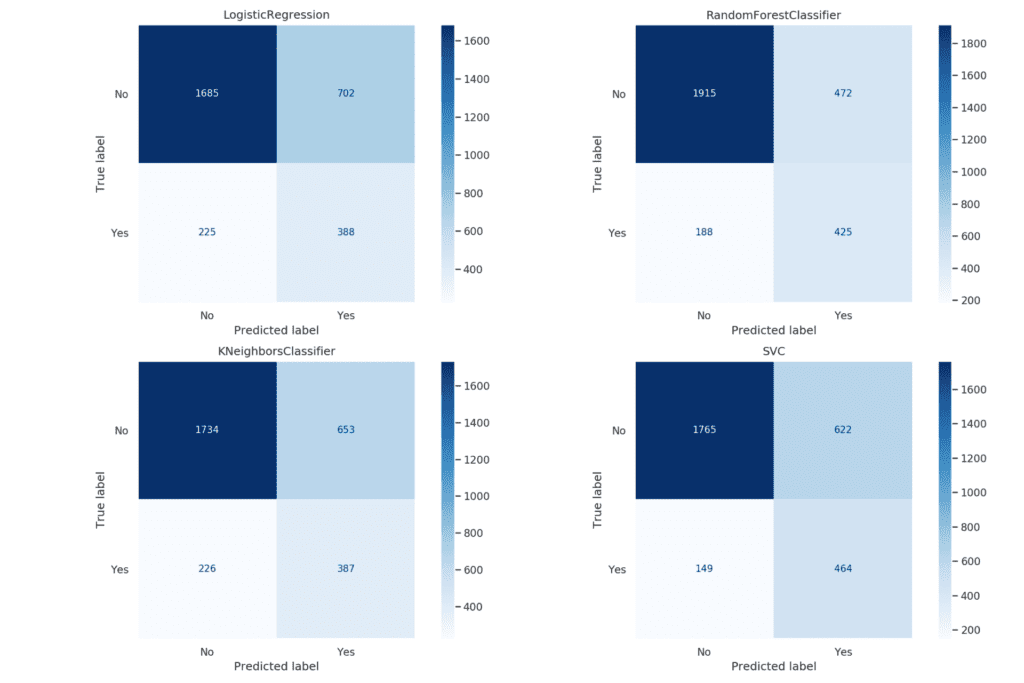
От изображението става ясно, че всички класификатори като цяло се справят добре с разпределянето на обекти в отрицателния клас, като Random Forest е с най-висок резултат - правилно разпределени 1915 случая от 2387. Моделът, използващ SVC, се справя най-добре при определяне на положителния клас, като правилно класифицираните обекти са 464 от 613.
Обща точност (Overall Accuracy) и Обща грешка (Overall error или Misclassification rate)
- Обща точност
Общата точност е показател, който ни дава информация за това каква част от всички случаи са правилно класифицирани от модела. Тя е една от най-често използваните метрики при оценка на работата на класификатор.
Формула:
ACC = \frac{TP + TN}{TP + TN + FP + FN} Изчислява се като общият брой правилно класифицирани обекти се разделя на всички случаи.
Модулът metrics на библиотеката Scikit-learn съдържа метод - accuracy_score(), който дава възможност за изчисляване на точността.
# Изчисляване на точността за всеки от класификаторите
score_lr = accuracy_score(y_test, lr_pred)
score_knn = accuracy_score(y_test, knn_pred)
score_svc = accuracy_score(y_test, svc_pred)
score_rf = accuracy_score(y_test, rf_pred)
# Запазване на получените резултати в DataFrame
scores = [score_lr, score_knn, score_svc, score_rf]
names = []
for cf in classifiers:
names.append(type(cf).__name__)
models_accuracy = pd.DataFrame({'Model': names, 'Accuracy': scores})
models_accuracyРезултат:
| Model | Accuracy | |
|---|---|---|
| 0 | LogisticRegression | 0.691 |
| 1 | RandomForestClassifier | 0.707 |
| 2 | KNeighborsClassifier | 0.743 |
| 3 | SVC | 0.780667 |
Само общата точност не е достатъчна за оценка на качеството на класификатор. Нужно е да се вземат под внимание и останалите метрики, които биха дали по-точна представа за това как се справя моделът.
- Обща грешка
Общата грешка е важна метрика и показва каква част от всички обекти класификаторът е разпределил в грешните класове.
Формула:
ERR = \frac{FP + FN}{TP + TN + FP + FN} = 1 - ACC Може да се изчисли като общият брой грешно класифицирани обекти се раздели на всички случаи или ако от 1 се извади точността.
# Изчисляване на грешката за всеки от класификаторите
error_lr = 1 - score_lr
error_rf = 1 - score_rf
error_knn = 1 - score_knn
error_svc = 1 - score_svc
# Запазване на получените резултати в DataFrame
err_scores = [error_lr, error_rf, error_knn, error_svc]
names = []
for cf in classifiers:
names.append(type(cf).__name__)
models_error = pd.DataFrame({'Model': names, 'Error Rate': err_scores})
Резултат:
| Model | Error Rate | |
|---|---|---|
| 0 | LogisticRegression | 0.309 |
| 1 | RandomForestClassifier | 0.219333 |
| 2 | KNeighborsClassifier | 0.293 |
| 3 | SVC | 0.257 |
Прецизност, Пълнота, Специфичност и F1 оценка (Precision, Recall, Specificity и F1-score)
Тези метрики са едни от най-популярните и често използвани при оценка на класификационен модел. Те се изчисляват за всеки клас поотделно или обобщено чрез осреднени стойности.
- Прецизност
Метриката прецизност показва каква част от обектите, класифицирани като положителни от модела, са в действителност положителни.
Формула:
Precision = \frac{TP}{TP + FP} - Пълнота
Пълнотата още се нарича True Positive Rate (TPR) или Sensivity. Тя е важна метрика, която ни дава информация за това каква част от положителния клас е била открита от класификатора.
Формула:
Recall = \frac{TP}{TP + FN}- Специфичност
Тази метрика още се нарича True Negative Rate (TNR). Тя показва каква част от отрицателния клас е била намерена от класификатора.
Формула:
Specificity = \frac{TN}{TN + FP}- F1 оценка
При увеличение на прецизността, пълнотата намалява и обратно. F1-score обобщава прецизността и пълнотата в една единствена стойност, като изчислява средно хармонично между тях, т.е. отношението между общия брой елементи и сумата на реципрочните им стойности. Стойността на този показател е максимална, когато прецизността и пълнотата са равни.
Формула:
F1-score = \frac{2}{\frac{1}{Recall} + \frac{1}{Precision}}Обобщаваща таблица
За нашия пример, стойностите за отделните показатели взимаме от класификационните отчети на всеки модел. Библиотеката Scikit-learn има метод classification_report() специално за тази цел.
Обобщаващата таблица, показваща отделните метрики, изглежда по следния начин:
| Model | Overall Accuracy | Overall Error | Precision (Class "No") | Precision (Class "Yes") | Recall (Class "No") - Specificity | Recall (Class "Yes") - Sensitivity | F1_score (Class "No") | F1_score (Class "Yes") | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Logistic Regression | 0.691 | 0.309 | 0.882199 | 0.355963 | 0.705907 | 0.632953 | 0.784268 | 0.455666 |
| 1 | Random Forest | 0.785 | 0.215 | 0.90969 | 0.481693 | 0.810222 | 0.686786 | 0.85708 | 0.566241 |
| 2 | K-Nearest Neighbors | 0.707 | 0.293 | 0.884694 | 0.372115 | 0.726435 | 0.631321 | 0.797792 | 0.46824 |
| 3 | SVC | 0.743 | 0.257 | 0.922153 | 0.427256 | 0.739422 | 0.756933 | 0.820739 | 0.546204 |
За осреднените стойности на метриките, обобщаващата таблица има следния вид:
| Model | Precision | Recall | F1_score | |
|---|---|---|---|---|
| 0 | Logistic Regression | 0.619081 | 0.66943 | 0.619967 |
| 1 | Random Forest | 0.695691 | 0.748504 | 0.71166 |
| 2 | K-Nearest Neighbors | 0.628405 | 0.678878 | 0.633016 |
| 3 | SVC | 0.674704 | 0.748177 | 0.683472 |
От двете таблици става ясно, че класификаторите, използващи методите Random Forest и SVC се справят най-добре, тъй като имат най-високи стойности по всички показатели.
ROC-крива (Receiver Operating Characteristic curve)
Тази крива е един от най-популярните начини за оценка на модел за бинарна класификация. При нея се съпоставят TPR (True Positive Rate) и FPR (False Positive Rate) при различни прагове (threshold). Пунктираната линия е случайно взет класификатор. Колкото повече се отдалечава от нея кривата на определен модел и се доближава до горния ляв ъгъл на графиката, толкова по-добър е той.
Площта под кривата (AUC) определя до каква степен класификаторът може да разграничава единия от другия клас при разпределяне на обектите. Стойностите на площта под кривата са в интервал между 0 и 1. Ако AUC е 1.0, тогава моделът е определил всички случаи правилно.
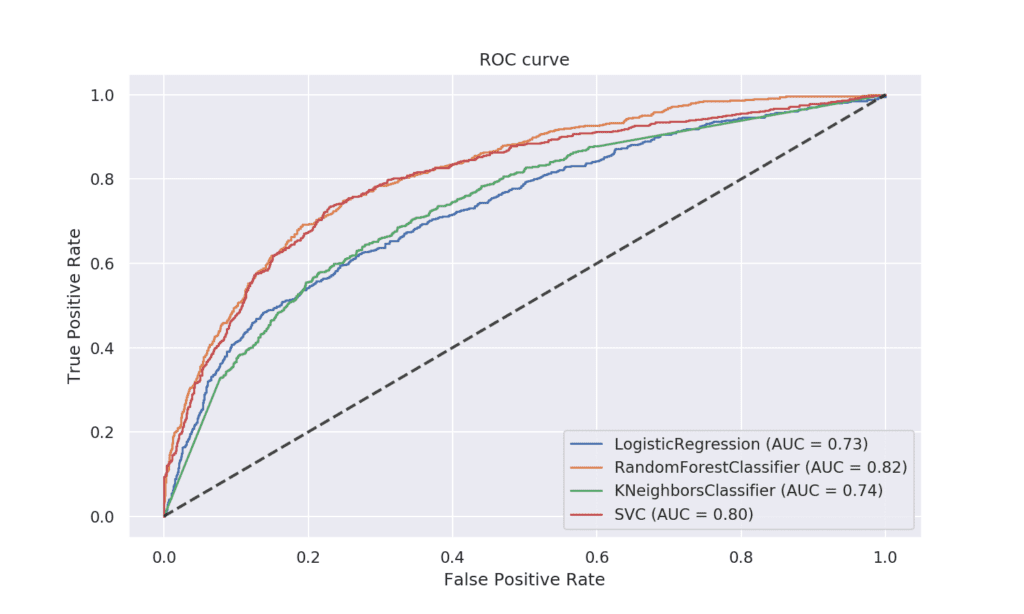
В нашия пример класификаторите, който се справят най-добре, са Random Forest и SVC, тъй като при тях площта под кривата е с най-високи стойности.
Precision-recall curve
Кривата прецизност-пълнота показва изменението на стойностите на прецизността и пълнотата при различни прагове, според които се разпределят данните към определен клас, като едното е за сметка на другото. Тази крива е един от начините да видим при кои стойности на прецизността и пълнотата моделът ще дава по-добри резултати. Колкото по-близо е до горния десен ъгъл, толкова по-добър е класификаторът.
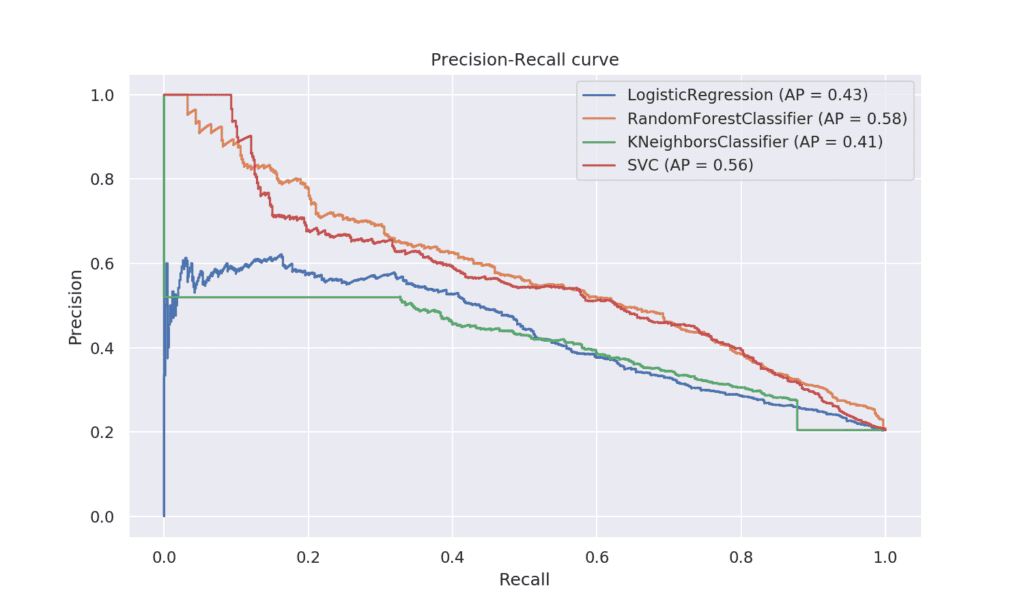
От изображението става ясно, че Random Forest и SVC са класификаторите, които дават най-добри резултати. Техните криви се доближават най-много до горния десен ъгъл на графиката.
На кои метрики да обръщаме повече внимание?
Всички изброени до този момент метрики дават полезна информация за оценка на качеството на модела за класификация. Общата точност е важна, но в доста от случаите може стойността ѝ да е подвеждаща. За по-добра оценка на това как се справя класификаторът са стойностите на прецизността, пълнотата и F1 оценката. Те дават информация за това колко добре той разпределя обектите в съответните класове. В зависимост от задачата се определя кой от класовете е по-важен и чрез настройки на съответен праг, може моделът да се изгради по такъв начин, че да покрива изискванията на бизнеса.
Искате да научите повече за машинното обучение?
Включете се в курса по машинно обучение и анализ на данни с Python.
Автор: Десислава Христова