Оптимизацията на модели е важна стъпка при решаване на задачи чрез методите на машинното обучение. При нея се стремим да открием тези параметри, при които получаваме оптимални резултати от моделите. Вместо да ги търсим чрез ръчни настройки, можем да използваме конкретни библиотеки и Optuna е създадена специално за тази цел. Тя улеснява процеса на подбор на най-добрите параметри.
В тази статия ще прегледаме как можем да оптимизираме модели чрез Optuna в контекста на конкретна практическа задача.
През какви стъпки трябва да преминем, когато използваме Optuna?
Optuna позволява откриването на оптималните параметри, като намира минимума или максимума на конкретна функция и извежда тези параметри, при които е получен най-добрият резултат. За използване на тази библиотека е нужно да преминем през 2 стъпки:
1/ Дефиниране на пространството от параметри вътре в целевата функция
За разлика от други библиотеки като Hyperopt, задаваме стойностите на параметрите вътре в целевата функция, което е доста по-гъвкаво. Optuna предоставя възможности за задаване на параметри от различни типове:
- категорийни - trial.suggest_categorical()
- цели числа - trial.suggest_int()
- дробни числа - trial.suggest_uniform(), trial.suggest_loguniform() или trial.suggest_discreteuniform()
Приложението им ще видите по-надолу в практическата задача.
2/ Създаване на study обект
Всички резултати от търсенето на оптималните параметри се съхраняват в специален обект - study. При създаването му се определя дали целевата функция ще се минимизира или максимизира. След това се прилага метода optimize, за да се оптимизира модела. Получените резултати могат да се изследват чрез различните свойства на обекта.
По подразбиране при Optuna се използва оптимизационният алгоритъм Tree Parzen Estimator (TPE), но има възможност за избор и на друг. Различните алгоритми са достъпни в модула samplers.
За разлика от други библиотеки, Optuna позволява по време на оптимизация да се прекратят конкретни опити, които според алгоритъма биха били неуспешни (Pruning of unpromising trials). В модула pruners има различни класове, които да определят какви са критериите за прекратяване на оптите. Например MedianPruner, който сравнява текущия резултат с медианата от предходните и ако той е по-лош, прекратява опита, или PercentilePruner, при който можем да зададем конкретен перцентил и се проверява дали полученият резултат е по-лош от конкретен % от предходните резултати. Ако това условие е изпълнено, опитът се прекратява.
Практическа задача
Ще използваме Optuna, за да решим една задача за бинарна класификация, при която трябва да се определи дали клиент ще се възползва от оферта за срочен депозит. Целевата променлива е с две възможни стойности - да или не. Данните, с които ще работим, са предварително изчистени - оставени са само май-важните колони, премахнати са екстремни стойности и т.н.
В следните статии можете да прочетете повече за различните стъпки от етапа на предварителна обработка на данните:
- Machine Learning: Как да обработим липсващи стойности при подготовката на данни за анализ?
- Machine Learning: Как да се справим с отличителни стойности (outliers)?
- Machine Learning: Защо е важно данните да са мащабирани?
- Machine Learning: Силата на визуализацията на данни. Коя графика какво ни показва?
- Machine Learning: Интерактивни визуализации с Python
- Machine Learning: Какво означава извадката да не е балансирана?
- Machine Learning: Как да кодираме категорийни променливи?
- Machine Learning: 5 начина да конструираме нови променливи
Примерът, който ще разгледаме по-надолу, можете да изтеглите от тук.
Оценка на модела без оптимизация
Ще изградим модел, който ще използва алгоритъма RandomForest при определяне на класовете на обектите. В таблицата по-надолу можете да видите някои негови параметри и техните стойности по подразбиране.
| Parameter | Default value | |
|---|---|---|
| 0 | criterion | gini |
| 1 | max_depth | None |
| 2 | max_features | auto |
| 3 | min_samples_leaf | 1 |
| 4 | min samples_split | 2 |
| 5 | n_estimators | 100 |
# Създаване на модела с параметри по подразбиране
rf = RandomForestClassifier()
# Обучение на модела
rf.fit(X_train_res, y_train_res)
# Тест на модела
rf_pred = rf.predict(X_test)Резултати:
| Metrics | Values | |
|---|---|---|
| 0 | Overall Accuracy | 0.70597 |
| 1 | Overall Error | 0.29403 |
| 2 | Precision | 0.649819 |
| 3 | Specificity | 0.751282 |
| 4 | Sensitivity | 0.642857 |
| 5 | F1_score | 0.64632 |
Моделът е с обща точност 71% и в 65% от случаите е определил, че даден човек ще се възползва от оферта за срочен депозит и той в действителност би я приел. Намерил е 75% от отрицателния клас и 64% от положителния.
Можете да научите по-подробно за основните метрики за оценка на класификационни модели в статията Machine Learning: Метрики за оценка на класификационни модели.
Оценка на модела след оптимизация
Създаване на пространството от параметри вътре в целевата функция е първата стъпка, която трябва да предприемем, при оптимизация на модели с библиотеката Optuna.
# Дефиниране на целевата функция
def objective(trial):
# Създаване на пространство от параметри и техните стойности
criterion = trial.suggest_categorical('criterion', ['entropy', 'gini'])
n_estimators = trial.suggest_int('n_estimators', 200, 500)
max_depth = trial.suggest_int('max_depth', 1, 11)
max_features = trial.suggest_categorical('max_features', ['sqrt', 'log2', None])
min_samples_leaf = trial.suggest_int('min_samples_leaf', 2, 14)
min_samples_split = trial.suggest_int('min_samples_split', 2, 8)
# Създаване на модел
clf = RandomForestClassifier(n_estimators=n_estimators,
criterion=criterion,
max_depth=max_depth,
max_features=max_features,
min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf)
# Получаване като резултат общата точност
return cross_val_score(clf, X_train_res, y_train_res, scoring='accuracy', n_jobs=-1, cv=5).mean()Общата точност е зададена като метрика за оценка на целевата функция, т.е. ще се търсят тези стойности на параметрите, при които имаме най-висок резултат.
Следващата стъпка е оптимизиране на модела. Необходимо е да създадем study обект, в който да съхраняваме резултатите от търсенето, след което да използваме метода optimize за извършване на оптимизацията.
# Създаване на study обект
study = optuna.create_study(direction='maximize')
# Извършване на оптимизацията
study.optimize(objective, n_trials=100)
# Съхраняване на оптималните параметри в отделна променлива
trial = study.best_trialOptuna позволява да изберем дали да максимизираме или минимизираме целевата функция чрез параметъра direction на метода create_study, а чрез задаване на n_trials на метода optimize указваме броя опити на алгоритъма да открие най-добрите параметри.
Оптималните параметри са следните:
| Parameters | Values | |
|---|---|---|
| 0 | criterion | gini |
| 1 | n_estimators | 328 |
| 2 | max_depth | 10 |
| 3 | max_features | sqrt |
| 4 | min_samples_leaf | 6 |
| 5 | min_samples_split | 7 |
След като сме намерили оптималните параметри, можем да изградим новия модел и да използваме получените за тях стойности.
# Създаване на модел с оптималните параметри
trainedforest = RandomForestClassifier(criterion = best_params['criterion'], max_depth = best_params['max_depth'],
max_features = best_params['max_features'],
min_samples_leaf = best_params['min_samples_leaf'],
min_samples_split = best_params['min_samples_split'],
n_estimators = best_params['n_estimators'])
# Обучение на модела
trainedforest.fit(X_train_res, y_train_res)
# Тест на модела
rf_new_pred = trainedforest.predict(X_test)Резултати:
| Metrics | Values | |
|---|---|---|
| 0 | Overall Accuracy | 0.759701 |
| 1 | Overall Error | 0.240299 |
| 2 | Precision | 0.740891 |
| 3 | Specificity | 0.835897 |
| 4 | Sensitivity | 0.653571 |
| 5 | F1_score | 0.694497 |
В 76% от случаите моделът правилно е класифицирал обектите в съответните класове. Открил е 74% от хората, които в действителност биха се възползвали от офертата, 84% от отрицателния клас и 65% от положителния.
Сравнение на резултатите
В сравнителната таблица по-надолу можете да видите как се различават стойностите на метриките при модел без и с оптимизация.
| Metrics | RF Default | RF Best Params | |
|---|---|---|---|
| 0 | Overall Accuracy | 0.70597 | 0.759701 |
| 1 | Overall Error | 0.29403 | 0.240299 |
| 2 | Precision | 0.649819 | 0.740891 |
| 3 | Specificity | 0.751282 | 0.835897 |
| 4 | Sensitivity | 0.642857 | 0.653571 |
| 5 | F1_score | 0.64632 | 0.694497 |
Има подобрение при всички класификационни метрики след оптимизация на модела. Това се наблюдава и при графиките на матриците на неточностите и тези на ROC и Precision-Recall кривите.
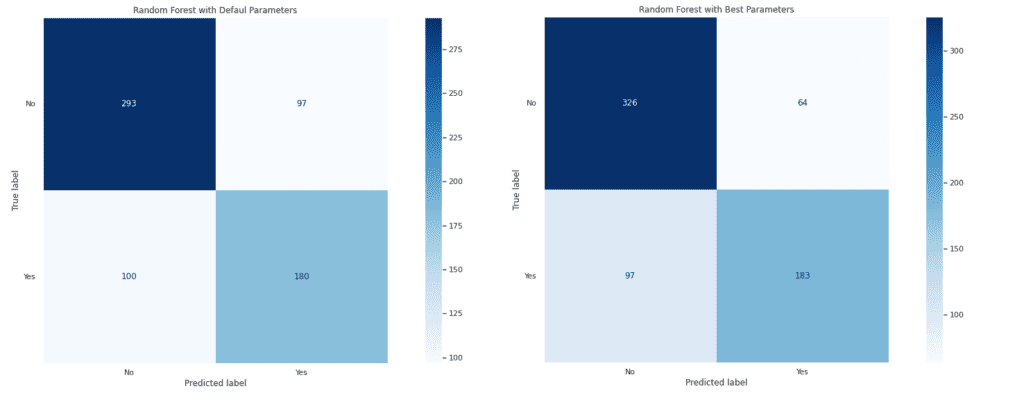
Оптимизираният модел се справя по-добре от този, който е с параметри по подразбиране, защото получените стойности за False Positive и False Negative са по-ниски. Правилно са определени 326 от общо 390 обекта от отрицателния клас и 183 от 280 от положителния.
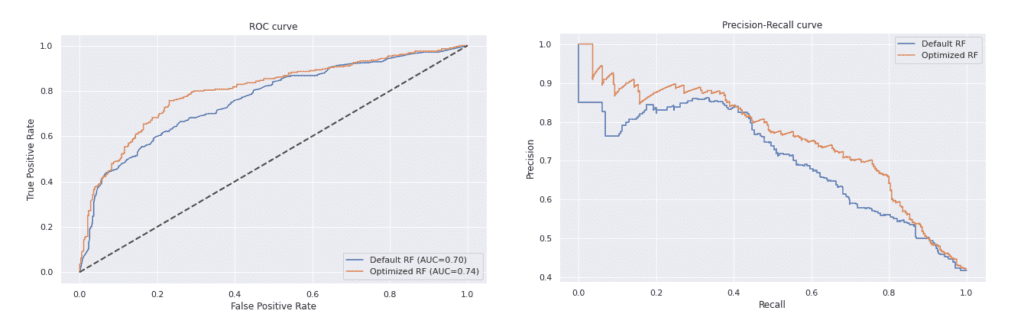
От двете визуализации става ясно, че моделът, който е с оптималните параметри, дава по-добри резултати. ROC кривата му е по-далеч от нулевия класификатор, а PR кривата е по-близо до горния десен ъгъл на графиката.
Извод
Optuna предоставя множество възможности при оптимизиране на модели за машинно обучение. Дефиниране на пространството от параметри вътре в целевата функция, позволява по-голяма гъвкавост. Нейни предимства пред други библиотеки са прекратяването на неуспешните опити по време на оптимизация и избор дали да се минимизира или максимизира целевата функция.
Искате да научите повече за машинното обучение?
Включете се в курса по машинно обучение и анализ на данни с Python.
Автор: Десислава Христова