Фокусът на тази статия е изборът на оптимални параметри след изграждане на модел за машинно обучение в контекста на конкретна практическа задача. Ще видим по-подробно какво представляват класовете RandomizedSearchCV и GridSearchCV на библиотеката Scikit-learn и ще оценим до колко добре се справя изграденият модел, като в единия случай ще използваме параметрите по подразбиране, а в другия – оптималните, открити от отделните класове.
Няма конкретна методика, въз основа на която сами да изчислим кои са оптималните параметри на модел за машинно обучение. Ръчният подбор е трудоемък процес, който отнема много време и пак не можем да сме сигурни, че сме се спряли на най-доброто решение. По-лесният вариант е да използваме рандомизирано или решетъчно търсене, които да ги открият вместо нас.
GridSearchCV преминава през всяка една комбинация от предварително зададени от нас параметри и техните стойности и накрая като резултат получаваме тези, при които моделът е получил най-добрия резултат на базата на определена метрика за оценка.
RandomizedSearchCV работи по подобен начин. Разликата е в това, че преминава само през част от комбинациите, като те се определят на случаен принцип.
Двата класа имат почти еднакви параметри и позволяват да задаваме различни ограничения върху процеса на оптимизация.
Някои от по-важните параметри на тези класове са:
- estimator – моделът, който сме изградили
- param_distribution – речник с параметрите и техните стойности
- cv – брой части при кръстосано валидиране
- n_iter – брой комбинации на параметрите и техните стойности при RandomizedSearchCV
- n_jobs – колко броя ядра на процесора да се използват
За примера, който ще разгледаме по-надолу, ще използваме извадка, съдържаща данни за клиенти на банка, която има 3354 реда и 5 колони. Задачата е за бинарна класификация и целта е да се определи дали даден клиент ще приеме оферта за откриване на срочен депозит или не, т.е. има 2 възможни стойности за целевата променлива – да и не. Данните, с които ще работим, са предварително изчистени – премахнати са екстремни стойности и излишни променливи, направен е визуален анализ и т.н.
Ако искате да научите повече за стъпките от етапа на предварителна обработка на данните, можете да прочетете в следните статии:
- Machine Learning: Как да обработим липсващи стойности при подготовката на данни за анализ?
- Machine Learning: Как да се справим с отличителни стойности (outliers)?
- Machine Learning: Защо е важно данните да са мащабирани?
- Machine Learning: Силата на визуализацията на данни. Коя графика какво ни показва?
- Machine Learning: Интерактивни визуализации с Python
- Machine Learning: Какво означава извадката да не е балансирана?
- Machine Learning: Как да кодираме категорийни променливи?
- Machine Learning: 5 начина да конструираме нови променливи
Примерът, който ще разгледаме по-надолу, можете да изтеглите от тук.
Изграждане на модел с параметри по подразбиране
За решаване на нашата задача, ще изградим модел, като използваме алгоритъма Random Forest, който чрез множество класификационни дървета може да определи към кой клас спадат обектите при постъпване на нови данни.
Основни негови параметри и техните подразбиращи стойности са:
- criterion = \’gini\’ – функцията, използвана за оценка на качеството на разделяне на данните
- max_depth = None – максималната дълбочина за всяко дърво
- max_features = \’auto\’ – максималния брой характеристики, взети под внимание при раделяне на данните
- min_samples_leaf = 1 – максималния брой наблюдения, които могат да се съхраняват в листо
- min_samples_split = 2 – минималния брой наблюдения, необходими за разделяне на данните
- n_estimators = 100 – брой дървета
# Създаване на модела с параметри по подразбиране
rf = RandomForestClassifier()
# Обучение на модела
rf.fit(X_train_res, y_train_res)
# Тест на модела
rf_pred = rf.predict(X_test)Стойностите на основните метрики за оценка на класификационни модели са следните:
| Metrics | Values | |
|---|---|---|
| 0 | Overall Accuracy | 0.713433 |
| 1 | Overall Error | 0.286567 |
| 2 | Precision | 0.661765 |
| 3 | Specificity | 0.764103 |
| 4 | Sensitivity | 0.642857 |
| 5 | F1_score | 0.652174 |
Моделът има 71% обща точност, т.е. в 71% от случаите е определил правилно класовете на конкретните обекти. В 66% от случаите обектите, които моделът е определил като положителни, в действителност са от положителния клас. Открити са 76% от отрицателния клас и 64% oт положителния.
Ако искате да научите по-подробно за тези метрики, можете да прочетете в статията Machine Learning: Метрики за оценка на класификационни модели.
# Откриване на разликата между определените от класификатора класове и тези в действителност
error = df_rf['Actual'].mean() - df_rf['Predicted'].mean()В тестовата извадка в 41.79% от случаите в действителност хората са приели офертата за срочен депозит, а резултатът от модела е 40.59%, т.е. имаме грешка от 1.20%.
Използване на GridSearchCV и RandomizedSearchCV
Първо ще зададем пространство от параметри, което да използваме при прилагане на RandomizedSearchCV.
# Създаване на речник с параметри и техни възможни стойности
rf_params_random = {'max_depth': range(1,11),
'criterion': ['gini', 'entropy'],
'max_features': ['sqrt', 'log2', None],
'n_estimators': [200, 500],
'min_samples_split': [2, 5, 10, 14],
'min_samples_leaf': [2, 4, 6, 8]
}За всеки един от параметрите са зададени няколко възможни стойности, като след това RandomizedSearchCV ще премине през общо 100 комбинации с тях, избрани на случаен принцип. Параметърът за кръстосана валидация е със стойност 3, т.е. RandomizedSearchCV ще премине 3 пъти през тези 100 комбинации и ще изведе тези стойности на параметрите, при които общата точност на модела е най-висока.
# Създаване на празен масив, в който да се съхраняват резултатите от RandomizedSearchCV
rf_params_best = []
for i in range(0,3):
# Използване на RandomizedSearchCV
rf_random_grid = RandomizedSearchCV(rf, rf_params_random, n_iter=100, cv=3,verbose=2, n_jobs=-1, scoring='accuracy')
# Обучение на модела
rf_random_grid.fit(X_train_res, y_train_res)
# Съхранение на резултатите в масива
rf_params_best.append(rf_random_grid.best_params_)Преминаваме през 3 итерации на RandomizedSearchCV с цел получаване на различни стойности за параметрите. Оптималните стойности от трите итерации след прилагане на RandomizedSearchCV са следните:
| Parameters | I | II | III | |
|---|---|---|---|---|
| 0 | n_estimators | 200 | 200 | 200 |
| 1 | min_samples_splt | 10 | 10 | 14 |
| 2 | min_samples_leaf | 2 | 2 | 2 |
| 3 | max_features | log2 | log2 | log2 |
| 4 | max_depth | 6 | 5 | 5 |
| 5 | criterion | entropy | gini | gini |
Общата точност и при трите итерации е приблизително 75%.
Ще използваме тези стойности при създаването на речник, който след това да подадем като параметър за търсене чрез GridSearchCV.
# Добавяне на параметрите и техните възможни стойности в речник
for key in rf_params_random:
for value in range(0,3):
rf_params_gs[key].append(rf_params_best[value][key])
# Премахване на дублиращи се стойности
new_rf_params_gs = {key:list(set(values)) for key, values in rf_params_gs.items()}Когато приложим GridSearchCV, той ще премине през всяка една комбинация 10 пъти, тъй като на параметъра за кръстосана валидация е зададена стойност 10.
# Използване на GridSearchCV за откриване на оптимални параметри
rf_grid = GridSearchCV(rf, new_rf_params_gs, cv=10, n_jobs=-1, verbose=2, scoring='accuracy')
# Обучение на модела
rf_grid.fit(X_train_res, y_train_res)
# Тест на модела
rf_grid.predict(X_test)Като оптимални параметри GridSearchCV е определил:
| Parameters | Values | |
|---|---|---|
| 0 | criterion | entropy |
| 1 | max_depth | 6 |
| 2 | max_features | log2 |
| 3 | min_samples_leaf | 2 |
| 4 | min_samples_split | 14 |
| 5 | n_estimators | 200 |
Обща точност: 0.7724184893913328
Общата точност при определяне на оптималните параметри от RandomizedSearchCV и GridSearchCV e на база тези данни, които са в извадката за обучение, а получените резултати върху тестовата извадка са следните:
| Metrics | Values | |
|---|---|---|
| 0 | Overall Accuracy | 0.755224 |
| 1 | Overall Error | 0.244776 |
| 2 | Precision | 0.728346 |
| 3 | Specificity | 0.823077 |
| 4 | Sensitivity | 0.660714 |
| 5 | F1_score | 0.692884 |
Общата точност е 76%, т.е. в 76% от случаите моделът правилно е определил класовете. Останалите метрики също са с високи стойности – 72% от разпределените от модела обекти в положителния клас в действителност са положителни. Отрити са 82% от отрицателния клас и 66% от положителния.
# Откриване на разликата между определените от класификатора класове и тези в действителност
error_best = df_rf_best['Actual'].mean() - df_rf_best['Predicted'].mean()В действителност 41.79% от обектите в тестовата извадка спадат към положителния клас. Моделът е определил правилно 37.91% от тях. Имаме грешка от 3.88%.
Сравнение на резултатите преди и след оптимизация на моделите
В сравнителната таблицата по-надолу можете да видите разликата в стойностите на различните метрики за оценка на класификационни модели за модела с параметри по подразбиране и след използване на RandomizedSearchCV и GridSearchCV.
| Metrics | RF Default | RF Best Params | |
|---|---|---|---|
| 0 | Overall Accuracy | 0.713433 | 0.755224 |
| 1 | Overall Error | 0.286567 | 0.244776 |
| 2 | Precision | 0.661765 | 0.728346 |
| 3 | Specificity | 0.764103 | 0.823077 |
| 4 | Sensitivity | 0.642857 | 0.660714 |
| 5 | F1_score | 0.652174 | 0.692884 |
Общата точност на оптимизирания модел е 76%, което е с 5% повече от тази на модела с параметри по подразбиране. Останалите метрики също са с по-добри резултати.
Подобрените резултати се забелязват както при матриците на неточностите за двата модела, така и при ROC и Precision-Recall (PR) кривите.
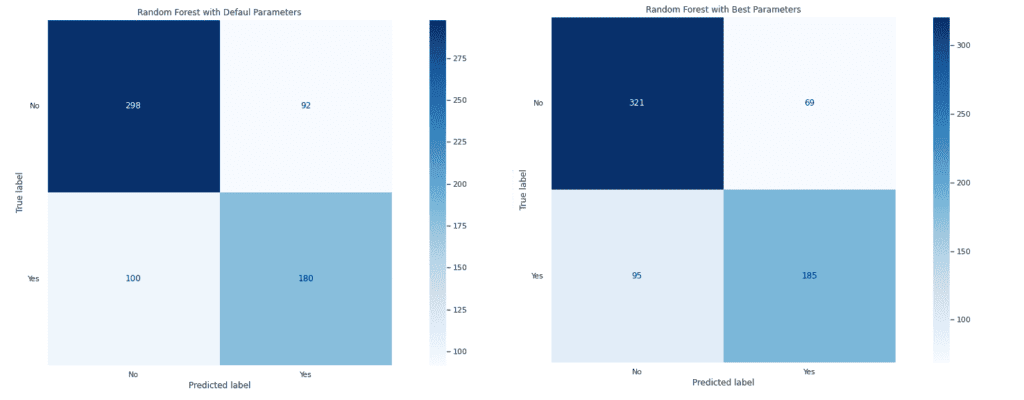
Оптимизираният модел се справя по-добре, като правилно разпределените обекти при отрицателния клас са 321 от 390, а при положителния 185 от 280.
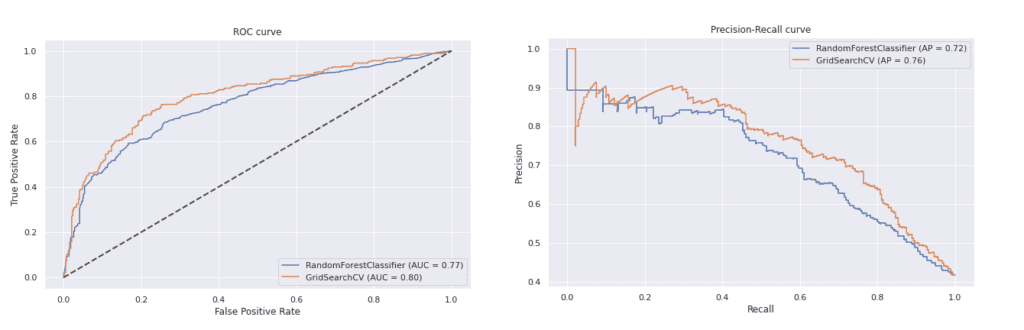
При двете криви оптимизираният модел дава по-добри резултати от този с параметрите по подразбиране. При ROC кривата е с малко по-голяма площ под кривата и е по-далеч от нулевия модел, а при PR кривите, оптимизирания модел се доближава повече до горния десен ъгъл на графиката.
Извод
Използването на RandomizedSearchCV в комбинация с GridSearchCV е един удобен начин за откриване на оптималните параметри на модел за машинно обучение. Единствените недостатъци за разлика от другите методи за оптимизация са, че може прилагането им да отнеме дълго време и че не се взимат под внимание предишни итерации при определяне на стойностите на параметрите.
Искате да научите повече за машинното обучение?
Включете се в курса по машинно обучение и анализ на данни с Python.
Автор: Десислава Христова